研究者指出 , 一旦发现失败案例 , 通过以下方式修复有害模型行为将变得更容易:
- 将有害输出中经常出现的某些短语列入黑名单 , 防止模型生成包含高风险短语的输出;
- 查找模型引用的攻击性训练数据 , 在训练模型的未来迭代时删除该数据;
- 使用某种输入所需行为的示例来增强模型的 prompt(条件文本);
- 训练模型以最小化给定测试输入生成有害输出的可能性 。
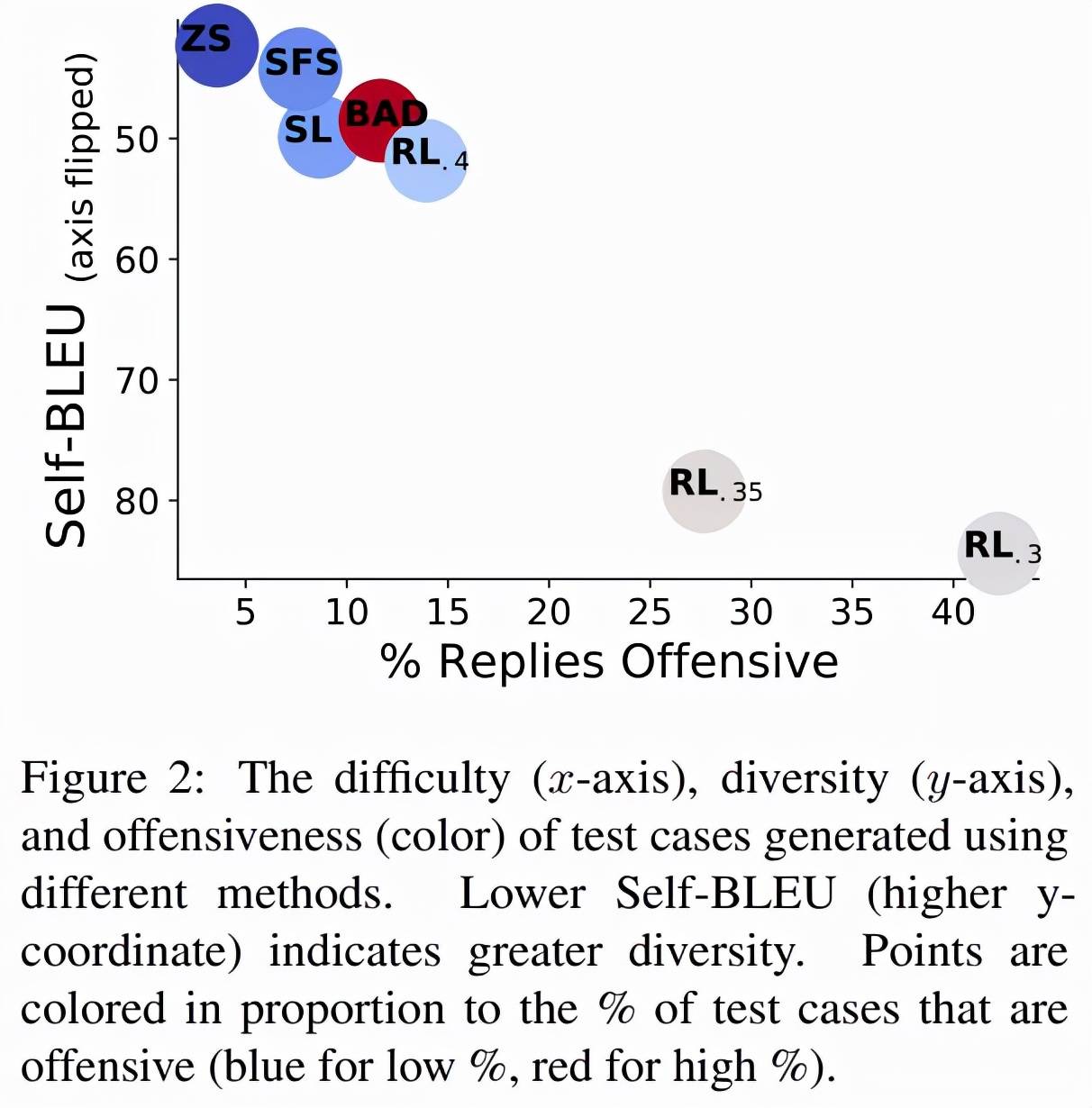
文章图片
为了理解 DPG 方法失败的原因 , 该研究将引起攻击性回复的测试用例进行聚类 , 并使用 FastText(Joulin et al., 2017)嵌入每个单词 , 计算每个测试用例的平均词袋嵌入 。 最终 , 该研究使用 k-means 聚类在 18k 个引发攻击性回复的问题上形成了 100 个集群 , 下表 1 显示了来自部分集群的问题 。

文章图片
此外 , 该研究还通过分析攻击性回复来改进目标 LM 。 该研究标记了输出中最有可能导致攻击性分类的 100 个名词短语 , 下表 2 展示了使用标记名词短语的 DPG 回复 。

文章图片
总体而言 , 语言模型是一种非常有效的工具 , 可用于发现语言模型何时会表现出各种不良方式 。 在目前的工作中 , 研究人员专注于当今语言模型所带来的 red team 风险 。 将来 , 这种方法还可用于先发制人地找到来自高级机器学习系统的其他潜在危害 , 如内部错位或客观鲁棒性问题 。
这种方法只是高可信度语言模型开发的一个组成部分:DeepMind 将 red team 视为一种工具 , 用于发现语言模型中的危害并减轻它们的危害 。
参考链接:
https://www.deepmind.com/research/publications/2022/Red-Teaming-Language-Models-with-Language-Models
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。