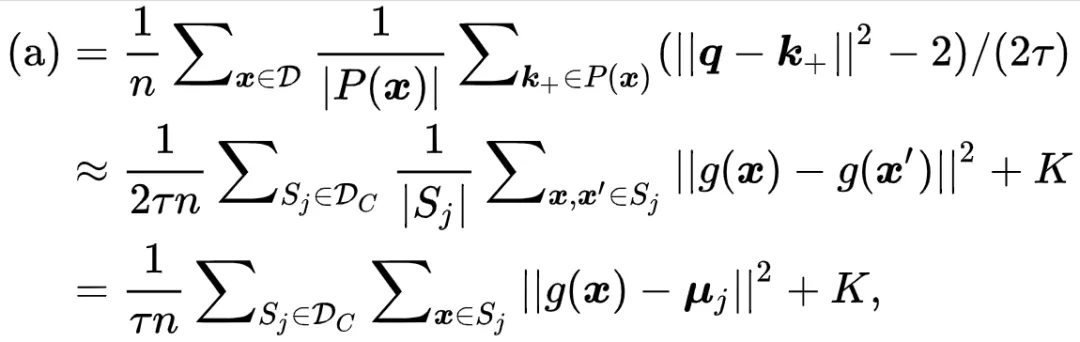
文章图片
其中
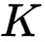
文章图片
是一个常数 ,
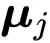
文章图片
是
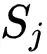
文章图片
的均值中心 。 这里研究者近似
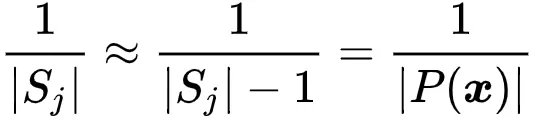
文章图片
因为
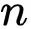
文章图片
通常很大 。 为简单起见 , 研究者省略了
文章图片
符号 。 可以看到 , Alignment 这一项能够最小化类内方差!
至此 , 研究者可以将 PiCO 算法解释为优化一个生成模型的 EM 算法 。 在 E 步 , 分类器将每个样本分配到一个特定的簇 。 在 M 步 , 对比损失将 embedding 集中到他们的簇中心方向 。 最后 , 训练数据将被映射到单位超球面上的混合 von Mises-Fisher 分布 。
EM-Perspective 。 为了估计似然
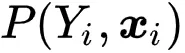
文章图片
, 研究者额外引入一个假设来建立候选标签集合与真实标签的联系 ,
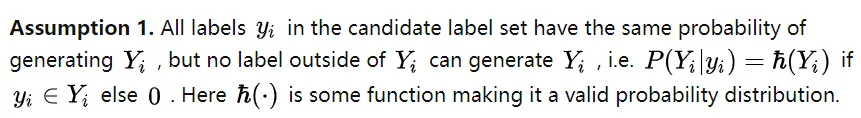
文章图片
由此 , 研究者证明 PiCO 隐式地最大化似然如下 ,
E-Step 。 首先 , 研究者在引入一组分布
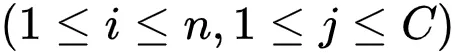
文章图片
, 且
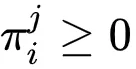
文章图片
若
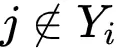
文章图片
,
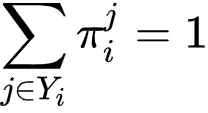
文章图片
。 令
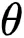
文章图片
为
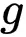
文章图片
的参数 。 研究者的目标是最大化如下似然 ,
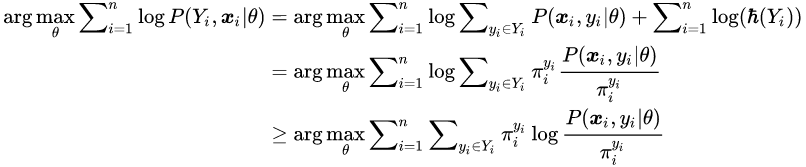
文章图片
最后一步推导使用了 Jensen 不等式 。 由于
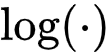
文章图片
函数是凹函数 , 当
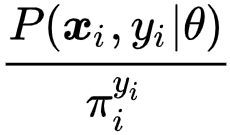
文章图片
是某些常数时等式成立 。 因此 , 研究者有 ,
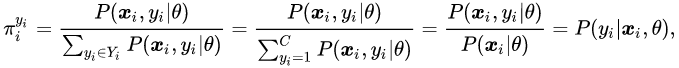
文章图片
即为类后验概率 。 在 PiCO 中 , 研究者使用分类器输出对其进行估计 。
为了估计
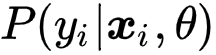
文章图片
, 经典的无监督聚类方法直接将样本分配给最近的聚类中心 , 如 k-Means 方法;在完全监督学习情况下 , 研究者可以直接使用 ground-truth 标签 。 然而 , 在 PLL 问题中 , 监督信号处于完全监督和无监督之间 。 根据研究者的实验观察 , 候选标签在开始时对后验估计更可靠;而随着模型训练 , 对比学习的原型会变得更加可信 。 这促使研究者以滑动平均方式更新伪标签 。 因此 , 研究者在估计类后验时有一个很好的初始化信息 , 并且在训练过程中会被平滑地改善 。 最后 , 由于每个样本对应一个唯一的标签 , 研究者采用 One-hot 预测
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。