通过对全局粗粒度的对齐 , 该研究将处在对齐后空间的 token、短语、物体特征序列拼接输入跨模态编码器 。
WPG 弱监督下的短语对齐
在跨模态学习阶段 , 该研究进一步显式地学习短语间的对齐关系 , 因为无法得到具体的图片区域和短语的匹配关系 , 研究者在 MVPTR 中使用类似现有的弱监督的 phrase grounding 方法进行学习 。
对于每一个共同编码的图片 - 文本对 , 该研究考虑跨模态编码器得到的 n 个短语的表征和 m 个物体特征的表征 , 通过余弦相似度计算每个短语 - 区域间的语义相似度 , 对这样 n*m 的相似度矩阵 。 基于多样例学习的方法对每个短语选择与其最相似的一个区域作为该短语在整个图片中匹配的得分 , 对所有短语进行平均后得到基于短语 - 区域匹配的图片 - 文本匹配得分 。 之后训练过程中可以根据图片 - 句子匹配的得分
类似之前在 ALBEF 工作中的发现 , 该研究在跨模态编码器的第三层训练 WPG 。 在模型完成各层次的匹配之后 , 最后模型完成高层次的语义推理任务 , 包括 ITM 和 MLM 。
ITM 图文匹配
图文匹配是视觉 - 语言预训练模型中常用的预训练任务 , 本质上是一个序列关系推断的任务 , 需要判断该多模态序列的图片和文本是否匹配 。
在 MVPTR 中 , 该研究直接通过使用跨模态编码器输出的 CLS token 特征 , 学习一个多层感知器来预测是否匹配的 2 分类得分 。 类似 ALBEF 的做法 , 该研究基于 VSC 任务输出的全局相似度从训练批次中采样得到较难的负样本进行 ITM 任务 。
【Fudan DISC推出跨视觉语言模态预训练模型MVPTR(已开源)】MLM 遮盖语言模型
遮盖语言模型同样是预训练模型中的常见任务 , 研究者认为其本质上是一个推理任务 , 因为对于描述性文本中的关键词语的遮盖和回复 , 比如数量词、形容词、名词、动作等实质上是从不同角度的推理任务 。 MLM 的设定与其他的预训练模型一致:随机遮盖或替换一部分的 token , 通过模型输出的表征 , 学习一个多层感知器预测原本的 token 。
实验
预训练设定
首先在模型结构上 , 该研究采取了与 BERT-base 一样的参数设定 , 两个单模态编码器均为 6 层的 Transformer 架构 , 参数初始化自 BERT-base 的前六层;跨模态编码器也为 6 层的 Transformer 架构 , 参数初始化自 BERT-base 的后六层 。
预训练的数据集上 , MVPTR 使用了和 VinVL 一样的数据集 , 包括 MSCOCO、FLickr30k、GQA、Conceptual Captions、SBU、OpenImages , 一共包括约 5M 的图片和 9M 的图文对 。 对于图片特征的抽取 , MVPTR 使用的 VinVL 提供的物体检测器 。 具体的模型和训练参数设置可以参考论文中的介绍 。
该研究对预训练后的 MVPTR 在多个下游任务上进行了微调 , 包括在 MSCOCO 和 Flickr30k 上的图文检索任务、VQA v2 上的视觉问答任务、SNLI-VE 上的视觉推理任务、RefCOCO + 上的短语表示指代任务 , 具体的微调方法和参数设定等请参考文章以及代码 。
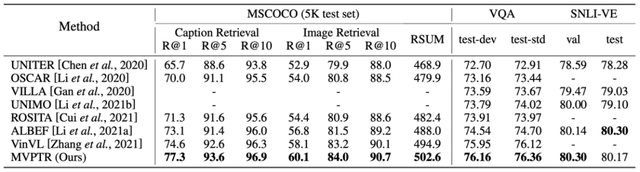
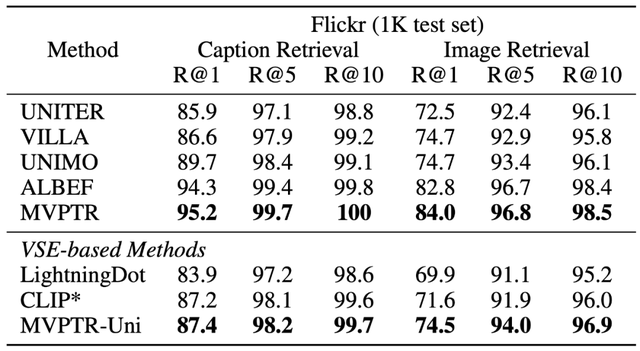
下图给出了在其中三个任务上结果:
文章图片
文章图片
可以看到预训练后的 MVPTR 在 MSCOCO 和 FLickr 上的图文检索任务上都有着明显的提升 , 表明多个层次的语义对齐能够很好地帮助模型学习到全局上图片 - 文本的匹配关系 。 同时研究者在 Flickr 数据集上验证了 MVPTR 中单模态编码器的语义对齐能力(表 2 的下半部分) , 并比较了 MVPTR 的单模态部分和其他基于单模态编码器的方法(CLIP * 为该实验中微调后的 CLIP-ViT32 版本) , 从结果可以看出通过引入额外的概念 , 以及物体概念的对齐任务 MCR , 单模态部分表现甚至要优于另外两个模型 CLIP , 尽管 MVPTR-Uni 的参数规模仅为另外两者的一半(6 层与 12 层 Transformer 架构) 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。