- 问题分解:把共识算法分为三个子问题 , 分别是领导者选举(leader election)、日志复制(log replication)、安全性(safety) 。
- 状态简化:对算法做出一些限制 , 减少状态数量和可能产生的变动 。
我们先来讨论状态简化这一点 , 在任何时刻 , 每一个服务器节点都处于leader , follower或candidate这三个状态之一 。
如果你了解过Paxos的话 , 就会知道 , 相比于Paxos , Raft这点极大简化了算法的实现 , 因为Raft只需考虑状态的切换 , 而不用像Paxos那样考虑状态之间的共存和互相影响 。
那么Raft具体是怎么做到这一点的呢?Raft把时间分割成任意长度的任期(term) , 任期用连续的整数标记 。
文章图片
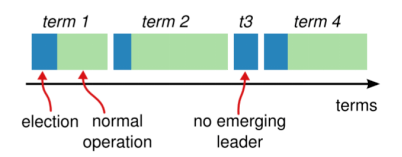
如上图 , 每一段任期从一次选举开始 。 在某些情况下 , 一次选举无法选出leader(比如两个节点收到了相同的票数) , 在这种情况下 , 这一任期会以没有leader结束;一个新的任期(包含一次新的选举)会很快重新开始 。 Raft保证在任意一个任期内 , 最多只有一个leader 。
Raft算法中服务器节点之间使用RPC进行通信 , 并且Raft中只有两种主要的RPC:
- RequestVote RPC(请求投票):由candidate在选举期间发起 。
- AppendEntries RPC(追加条目):由leader发起 , 用来复制日志和提供一种心跳机制 。
接下来 , 我们具体讨论领导者选举、日志复制和安全性三个子问题 。
2、领导者选举、日志复制、安全性
1)领导者选举
首先是领导者选举(leader election) 。 Raft内部有一种心跳机制 , 如果存在leader , 那么它就会周期性地向所有follower发送心跳 , 来维持自己的地位 。 如果follower一段时间没有收到心跳 , 那么他就会认为系统中没有可用的leader了 , 然后开始进行选举 。
开始一个选举过程后 , follower先增加自己的当前任期号 , 并转换到candidate状态 。 然后投票给自己 , 并且并行地向集群中的其他服务器节点发送投票请求 。 最终会有三种结果:
- 它获得超过半数选票赢得了选举 -> 成为主并开始发送心跳 。
- 其他节点赢得了选举 -> 收到新leader的心跳后 , 如果新leader的任期号不小于自己当前的任期号 , 那么就从candidate回到follower状态 。
- 一段时间之后没有任何获胜者 -> 每个candidate都在一个自己的随机选举超时时间后增加任期号开始新一轮投票 。
新主选出来后 , 就进入日志复制(log replication)阶段了 。
Leader被选举出来后 , 开始为客户端请求提供服务(你可能会问 , 客户端怎么知道新leader是哪个节点呢?有一个很简单的方法 , 客户端随机发送指令到一个节点 , 如果这个节点不是主 , 那么它就返回主的信息给客户端) 。 Leader接收到客户端的指令后 , 会把指令作为一个新的条目追加到日志中去 , 然后并行发送给follower , 让它们复制该条目 。 当该条目被超过半数的follower复制后 , leader就可以在本地执行该指令并把结果返回客户端 。
在此过程中 , leader或follower随时都有崩溃或缓慢的可能性 , Raft必须要在有宕机的情况下继续支持日志复制 , 并且保证每个副本日志顺序的一致(以保证复制状态机的实现):
- 如果有follower因为某些原因没有给leader响应 , 那么leader会不断地重发追加条目请求 , 哪怕leader已经回复了客户端 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。