信度评估方法采用的是强化学习构建置信度框架 。 主要分为三个部分:
1. 用 BERT 等语言模型等抽取语义向量
2. 利用双向长短期记忆方式组合全局向量
3. 强化学习模块根据人工打分拟合相关标准 , 输出置信度分数 。
文章插图
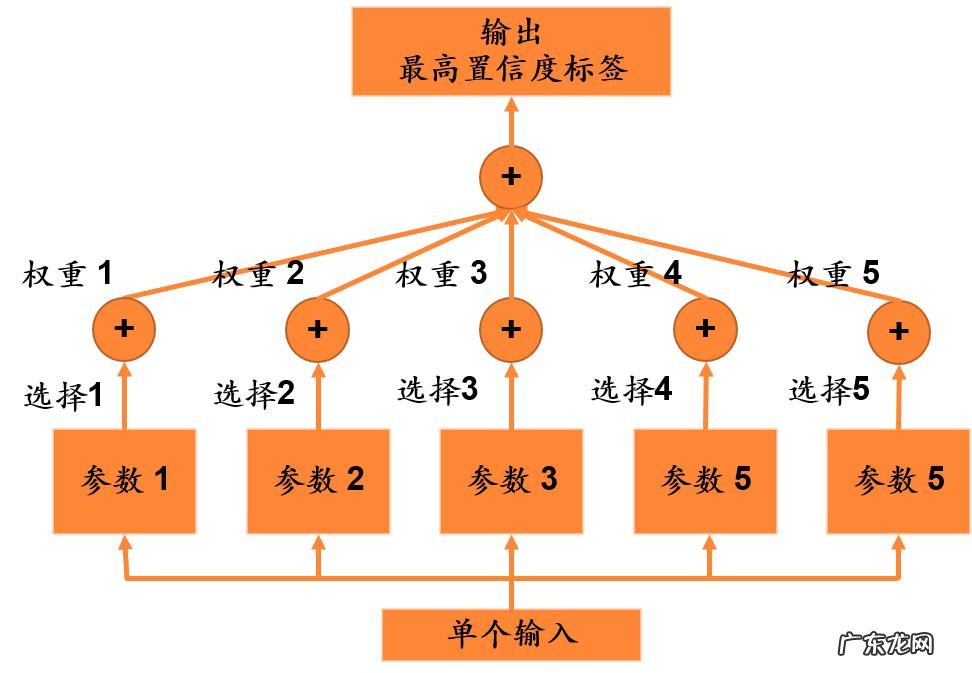
此外 , 还可以尝试通过 Bagging 思想构建置信度框架 。 模型 pipeline 有 4 个阶段:
1. 利用 Bagging 思想 , 从数据中抽样 5 份 , 训练出 5 套模型参数;
2. 在少量测试集上测试各套参数性能 , 根据性能例如 F1 值 , 分配各模型置信度权重;
3. 各套参数选择某个标签后 , 在结果统计中累加对应参数权重;
4. 最终输出累加置信度最高标签 。
4
技术应用

文章插图
经过实验证明 , 改进后的语言模型在语义相似度、多分类、语义蕴含等多类型国际公开数据集上测试精度较 BERT 模型的提升大多在 10%-20% , 但召回率下降 20%-50%;在实际项目中从舆情中提取公司标签的模型精度提升 11 个百分点 , 达到 93% 。
这在商业上非常有价值 , 例如虽然召回率降低了 50 个百分点 , 但意味着只有一半的模型需要人工干预 , 另一半的模型完全可以交给自动化 , 这远比模型无法上线要好的多 。
在金融领域 , 例如选股 , 模型的精准度是首先需要考虑的 , 其他指标可以稍差 。 例如从 1000 只备选股票中模型只选出了 50 只良好股票 , 可能会错过 50 只良好股票 。 但这种错过也是允许的 , 毕竟模型会 ” 保证 ” 选出来的 50 只股票大概率能够赚钱或有超额收益 。
雷峰网雷峰网
- 中国雷达技术世界排名 2021雷达探测器品牌排行榜
- 香港四大支柱产业 香港十大知名高新技术产业
- 又是年底时,是时候给技术宅安排一款好用的移动云 云主机了
- 蔬菜啥时运,算法来较劲!盒马供应链新技术入围国际大奖
- 职业技术学院排名全国2020 2021中国高职院校排行榜
- 技术的轮回:投资者为什么会错过英伟达、特斯拉、苹果?
- 阿里的云计算直播技术Apsara Live正式出海
- SUV品牌销量排名前十名推荐 – 汽车维修技术网 各种车销量排行榜大全
- SUV品牌销量排名前十名推荐 – 汽车维修技术网 汽车销量排行榜前十名品牌大全
- 抖音福袋有什么必中技术?抖音如何发福袋?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。