
文章图片
方法
神经网络视频传输是在传输互联网视频时利用 DNN 来节省带宽 。 与传统的视频传输系统不同 , 它们用低分辩率视频和内容感知模型取代了高分辨率视频 。 如上图所示 , 整个过程包括三个阶段:(i)在服务器上对每个视频段的模型进行训练;(ii) 将低分辨率视频段与内容感知模型一起从服务器传送到客户端;(iii) 客户端上对低分辨率视频进行超分工作 。 但是 , 该过程需要为每个视频段传输一个模型 , 从而导致额外的带宽成本 。 所以该研究提出了一种压缩方法 , 利用 CaFM 模块结合联合训练的方式 , 将模型参数压缩为原本的 1% 。
动机和发现
图 2

文章图片
该研究将视频分成 n 段 , 并相应地为这些视频段训练 n 个 SR 模型 S1、S2 ...Sn 。 然后通过一张随机选择的输入图片(DIV2K) 来分析 S1、S2...Sn 模型间的关系 。 该研究在图 2 中可视化了 3 个 SR 模型的特征图 。 每张图像代表某个通道( channel)的特征图 , 为了简单起见 , 该研究只可视化了一层 SR 模型 。 具体来说 , 该研究将特征图表示为
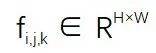
文章图片
, 其中 i 表示第 i 个模型 , j 表示第 j 个 通道 , k 表示 SR 模型 的第 k 层卷积 。 对于随机选择的图像 , 可以计算
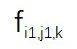
文章图片
和

文章图片
之间的余弦距离 , 来衡量这两组特征图之间的相似度 。 对于图 2 中的特征图 , 该研究计算了
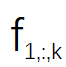
文章图片
,

文章图片
和
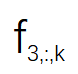
文章图片
之间的余弦距离矩阵 。 如图 3 所示 , 研究者观察到虽然 S1 , S2 ...Sn 是在不同的视频段上训练的 , 但根据图 3 中矩阵的对角线值可以看出“对应通道之间的余弦距离非常小” 。 该研究计算了 S1、S2 和 S3 之间所有层的余弦距离的平均值 , 结果分别约为 0.16 和 0.04 。 这表明虽然在不同视频段上训练得到了不同的 SR 模型 , 但是
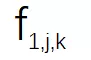
文章图片
和
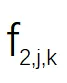
文章图片
之间的关系可以通过线性函数近似建模 。 这也是该研究提出 CaFM 模块的动机 。
图 3

文章图片
内容感知特征调制模块(CaFM)
该研究将内容感知特征调制 (CaFM) 模块引入基线模型(EDSR) , 以私有化每个视频段的 SR 模型 。 整体框架如图 4 所示 。 正如上文动机中提到的 , CaFM 的目的是操纵特征图并使模型去拟合不同的视频段 。 因此 , 不同段的模型可以共享大部分参数 。 该研究将 CaFM 表示为 channel-wise 线性函数:
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。