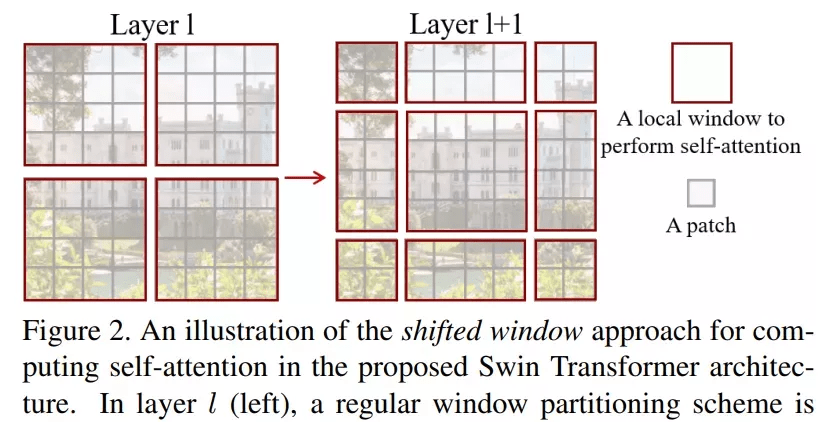
文章图片
模型本身具有的特性使其在一系列视觉任务上都实现了颇具竞争力的性能表现 。 其中 , 在 ImageNet-1K 数据集上实现了 86.4% 的图像分类准确率、在 COCO test-dev 数据集上实现了 58.7% 的目标检测 box AP 和 51.1% 的 mask AP 。 目前在 COCO minival 和 COCO test-dev 两个数据集上 , Swin-L(Swin Transformer 的变体)在目标检测和实例分割任务中均实现了 SOTA 。
文章图片
此外 , 在 ADE20K val 和 ADE20K 数据集上 , Swin-L 也在语义分割任务中实现了 SOTA 。
最佳学生论文奖
- 获奖论文:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
- 作者机构:苏黎世联邦理工学院、微软
- 论文地址:https://arxiv.org/pdf/2108.08291.pdf
- 项目地址:github.com/cvg/pixel-perfect-sfm (http://github.com/cvg/pixel-perfect-sfm)

文章图片
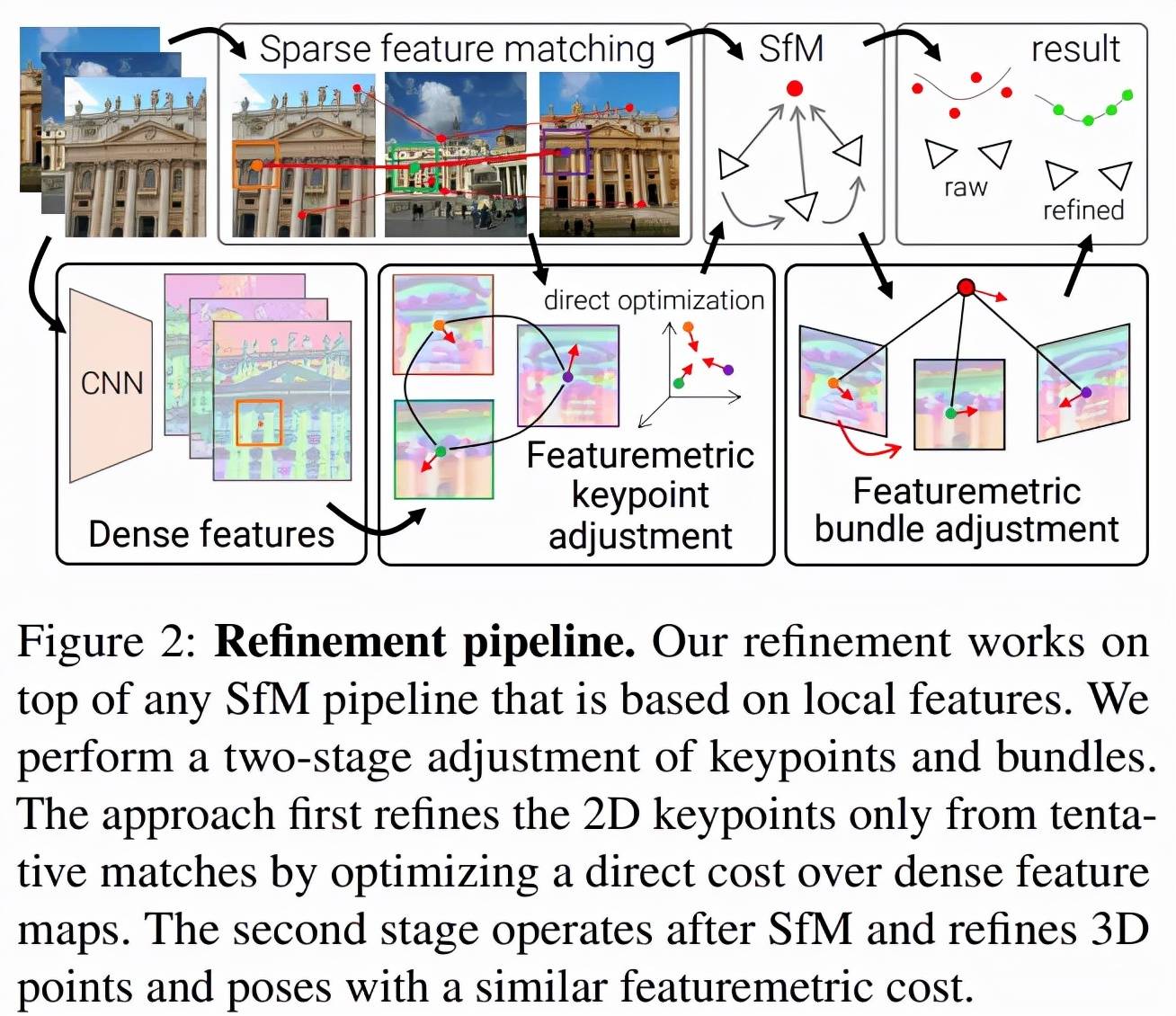
论文摘要:在多个视图中寻找可重复的局部特征是稀疏 3D 重建的基础 。 经典的图像匹配范式一次性检测每个图像的全部关键点(keypoint) , 这可能会产生定位不佳的特征 , 使得最终生成的几何形状出现较大错误 。 研究者通过直接对齐来自多个视图的低级图像信息来细化运动恢复结构(structure-from-motion , SFM)的两个关键步骤:首先在任何几何估计之前调整初始关键点位置 , 然后细化点和相机姿态作为一个后处理 。 这种改进对大的检测噪声和外观变化具有稳健性 , 因为它基于神经网络预测的密集特征优化了特征度量误差 。 这显著提高了相机姿态和场景几何的准确性 , 并适用于各种关键点检测器、具有挑战性的观看条件和现成的(off-the-shelf)深度特征 。 该系统可以轻松扩展到大型图像集合 , 从而实现像素完美的大规模众包定位 。 该方法现已封装为 SfM 软件 COLMAP 的附加组件 。
细化几何原本是一种局部操作 , 但该研究表明局部密集像素可以起到较大的作用 。 SfM 通常尽可能早地丢弃图像信息 , 该研究借助直接对齐用几个步骤替代了 SfM 。 下图 2 是该方法的概览:
文章图片
最佳论文荣誉提名奖
今年有四篇论文获得 ICCV 2021 最佳论文荣誉提名奖 。
- 论文 1:Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
- 作者机构:谷歌、加州大学伯克利分校
- 论文地址:https://arxiv.org/pdf/2103.13415.pdf

文章图片
论文摘要:NeRF(neural radiance fields)使用的渲染过程以每像素单个光线对场景进行采样 , 因此当训练或测试图像以不同分辨率观察场景内容时 , 可能会产生过度模糊的渲染 。 该研究提出了 mip-NeRF , 它以连续值的比例表示场景 。 他们通过高效地渲染消除反锯齿圆锥锥体( anti-aliased conical frustums)取代光线 , mip NeRF 减少了混叠瑕疵(aliasing artifacts) , 并显著提高了其表示精细细节的能力 , 同时比 NeRF 快 7% , 而大小仅为 NeRF 的一半 。
与 NeRF 相比 , mip NeRF 在数据集上降低了 17% 的平均错误率 , 在具有挑战性的多尺度变体上降低了 60% 的平均错误率 。 此外 , Mip NeRF 还能够在多尺度数据集上与超采样 NeRF 的精度相匹配 , 同时速度快 22 倍 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。