
文章图片
对于 Podcast 数据 , WeNet使用国内最好的商业语音识别系统之一 , 对 Podcast 数据进行切分 , 并生成切分后音频和其所对应的文本作为候选平行数据 。
数据校验
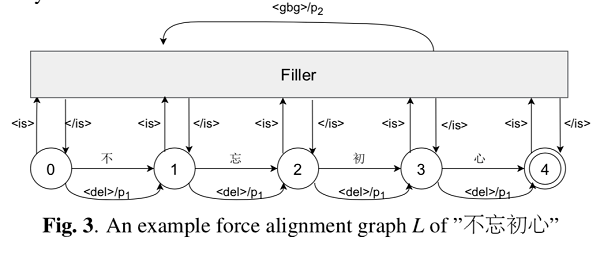
OCR 字幕识别和 ASR 语音转写生成的候选平行数据中不可避免的存在一些错误 , 如人工字幕本身有错误 , 字幕时间不准 , OCR 识别错误 , 转写错误等 。 为了检测该错误 , WenetSpeech 中提出一种基于端到端的自动标注错误检测算法 , 如下图所示 。 该算法首先根据候选平行数据的文本(ref)构建一个一个强制对齐图 , 该图中允许在任意位置进行删除、插入和替换操作 。 然后将候选平行数据的语音输入到该图进行解码得到识别结果(hyp) , 最终计算 ref 和 hyp 的编辑距离并做归一化从而得到该候选平行数据的置信度 。 当候选语音和文本一致性高时 , ref 和 hyp 一致性高 , 置信度高 , 反之 , 当候选语音和文本一致性低时 , 置信度低 。
文章图片
WenetSpeech 中选取置信度>=95%的数据作为高质量标注数据 , 选取置信度在0.6和0.95之间的数据作为弱监督数据 。 关于该算法的详细内容 , 请参考我们的论文 。
排行榜
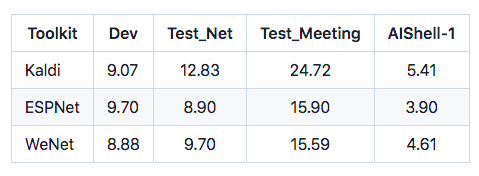
除了训练中校验用途的 Dev 集外 , 还设计了两个人工精标测试集 , 互联网测试集 Test_Net 和会议测试集 Test_Meeting , 作为“匹配”和“不匹配”测试 , 同时提供三个语音识别主流工具包(Kaldi , ESPNet , WeNet)上搭建的基线系统 , 方便使用者复现 。 在 10000+ 小时的高质量标注数据上 , 目前三个系统的语音识别率如下表所示(结果为 MER% , 中文算字错误 , 英文算词错误) 。
文章图片
WenetSpeech 2.0
虽然 WenetSpeech 将开源中文语音识别训练数据规模提升到一个新的高度 , 然而希望进一步进行扩展和完善:
1.从领域角度 , 现有数据集在口音、中英文混合、会议、远场、教育、电话、语音助手等场景仍覆盖不足 。
2.从数据量角度 , 现有的2万+小时的总数据 , 对于无监督学习仍然远远不够 。
因此 , WenetSpeech 在设计之初 , 就考虑到了未来做进一步扩展 。 目前出门问问已经开始 WenetSpeech 2.0 的工作 , 并且在 2.0 中 , 希望更多的行业机构和开发者能参与进来 , 能够集行业之力更好、更快地去做一个更大更泛化的数据集 , 从而进一步反哺和造福整个行业 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。