Cooka , 当前的 AutoML 不仅可以参与建模过程 , 还能将自动生成的 AI 模型更快投入到实践中 。
整个 DAT 工具栈以面向任务分类 , 可以同时满足结构化数据的建模和非结构化数据(CV、NLP)的建模 , 覆盖了从数据工程师、AI 开发者、AutoML 工具开发者、再到非技术背景人员的广大范围 。
这套工具无需绑定特定的云服务或硬件 , 只需要电脑设置好 Python 等环境就可以上手 , 也支持大规模数据和集群计算 。
DAT 的目标是打造 AutoML 的全方位能力 , 并不只针对某一个建模的场景和目标 , 目前市面上还没有哪个产品和 DAT 的定位是完全重合的 。
节约百倍开发时间
作为一个高度独立且开源的产品 , DAT 相对其他 AutoML 工具有很大优势 。
首先是使用最好的技术 , 九章云极 DataCanvas 内置了几种对高维空间非常有效的搜索算法 , 包括蒙特卡洛树搜索、强化学习算法、进化算法 , 并引入了元学习(Meta-learning)方法来加速搜索过程 , 利用历史搜索和评估结果来更准确和高效的指导搜索方向 , 减少搜索迭代次数 。
在 AutoML 的实际应用过程中 , 真正消耗算力的部分是模型评估 。 一个基本的搜索过程是:从搜索空间中采样、评估样本效果、反馈给搜索算法指导下次采样的方向 , 然后重复这个过程直到找到满意的样本 。
「我们引入了很多方法来降低评估成本 , 比如低保真预热、同路径数据链路缓存、模型训练的 Pruning 等等 。 HyperGBM 通常只需要人工单次训练时间的 10 倍左右的时间就可以完成整个 AutoML 的过程 , 从总成本上看大大优于人工建模 。 」杨健说道 。
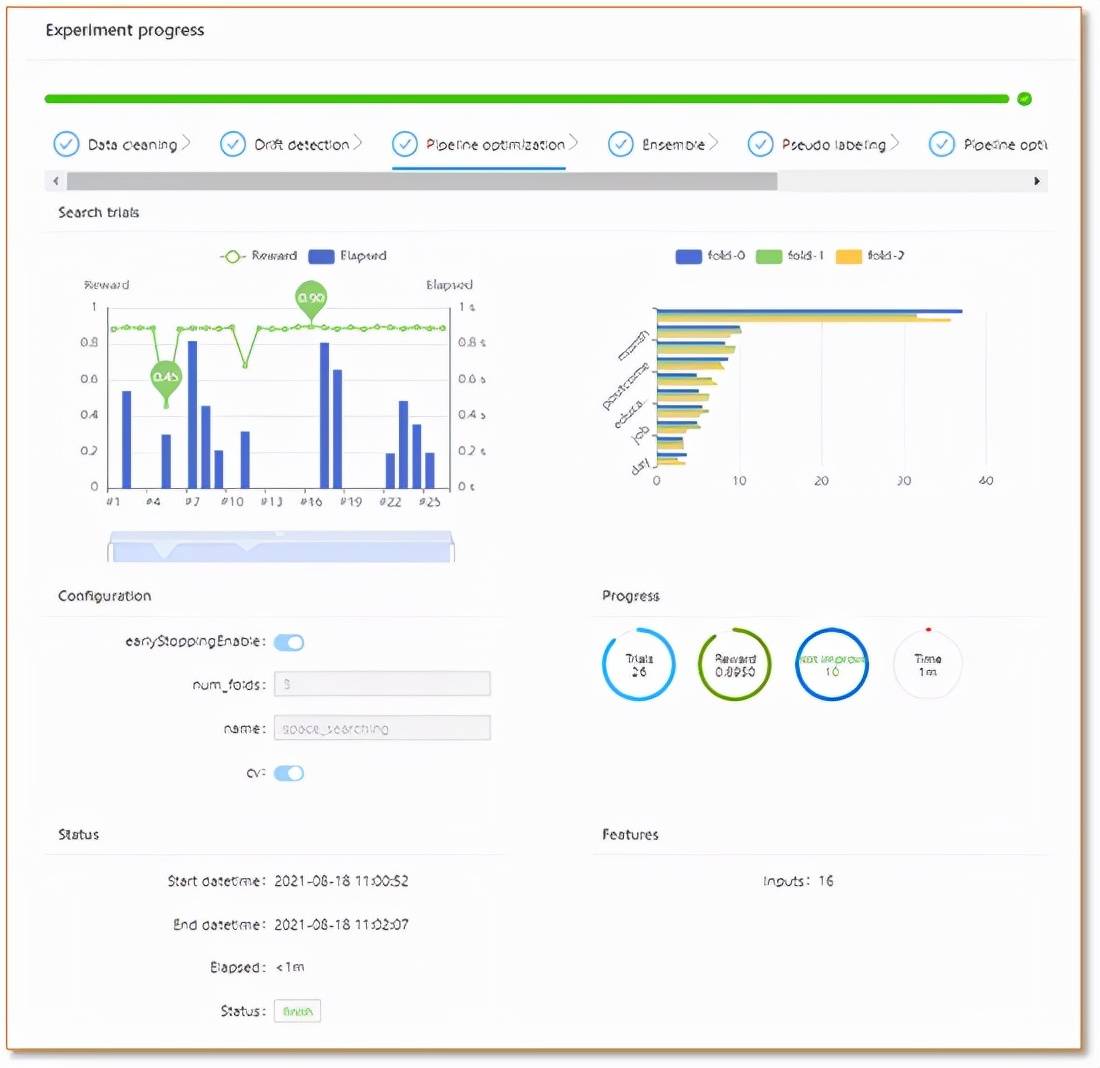
文章图片
DAT 在 notebook 中的可视化运行图 。
在实际环境中 , 机器学习模型经常会遭遇「概念漂移」的挑战:AutoML 在静态数据下表现很好 , 但实际应用场景下 , 数据是实时产生的 , 特征也在不断发生变化 。 如何在这样的情况下保持足够高的判断水准?
在 DAT 中 , 这个问题也是可以被自动处理的 , 其引入了一个半监督学习方法——对抗验证(Adversarial Validation) , 这一思想来自于 GAN 。 通过这种半监督的方法 , 我们不需要看到真实结果(y-true)就可以评估是否发生了数据漂移 , 哪些特征发生了漂移 , 然后对它们做相应的处理 。
在传统机器学习建模过程中 , 开发者需要反复实验 , 进行特征处理、模型选择、调参等等工作 , 训练一个实用化模型至少要几十到上百次的反复训练 。 相比人力 , AutoML 带来的效率提升可以达到上百倍 。 手工建模需要数周数月的时间 , AutoML 可以在一天以内完成 。 如果一个实习生从零开始学习使用 DAT 构建算法 , 只需要两个星期时间就能提交结果 , 很多工作只需要几十行代码 。
而且使用 DAT 完成的效果更稳定 。 「手工建模的质量取决于个人的能力 , 有很大的不确定性 , AutoML 的算法不会有这样的问题 。 」杨健说道 。
对阵 Kaggle 大师 , 获得数据竞赛冠军
如果像自动驾驶一样把 AutoML 的自动化程度进行分级的话 , 它的发展速度相对更快:Level 2 可以对应 XGboost 这样的机器学习包 , Level 3 对应自动化调参的算法优化工具 , Level 4 可以实现端到端自动化建模 , 对应如今的 DAT;而 AutoML 最终的目标是完全不依赖领域专家的建模 , 甚至是根据数据变化自我进化的系统 。
由于 DAT 是开源的 , 人们可以自行安装使用、感受 AutoML 的能力:其中的两个工具 DeepTables 和 HyperGBM 和谷歌 AutoML Tables 同样能解决结构化数据建模问题 , 在几个公开数据集的测试上看 Google AutoML Tables 要比 DAT 慢一个量级 , 而且谷歌的工具是云服务的一部分 , 需要先付费 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。