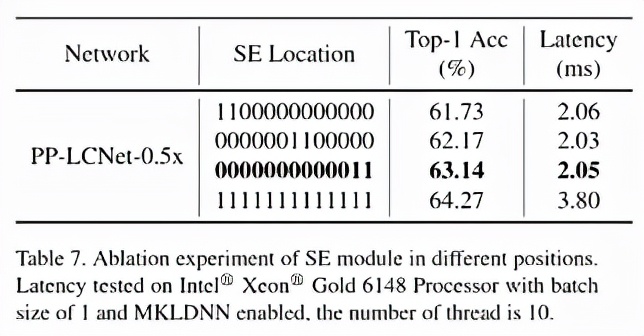
文章图片
最终 , PP-LCNet 中的 SE 模块的位置选用了表格中第三行的方案 。
更大的卷积核
在 MixNet 的论文中 , 作者分析了卷积核大小对模型性能的影响 , 结论是在一定范围内大的卷积核可以提升模型的性能 , 但是超过这个范围会有损模型的性能 , 所以作者组合了一种 split-concat 范式的 MixConv , 这种组合虽然可以提升模型的性能 , 但是不利于推理 。 我们通过实验总结了一些更大的卷积核在不同位置的作用 , 类似 SE 模块的位置 , 更大的卷积核在网络的中后部作用更明显 , 下表展示了 5x5 卷积核的位置对精度的影响:

文章图片
实验表明 , 更大的卷积核放在网络的中后部即可达到放在所有位置的精度 , 与此同时 , 获得更快的推理速度 。 PP-LCNet 最终选用了表格中第三行的方案 。
GAP 后使用更大的 1x1 卷积层
在 GoogLeNet 之后 , GAP(Global-Average-Pooling)后往往直接接分类层 , 但是在轻量级网络中 , 这样会导致 GAP 后提取的特征没有得到进一步的融合和加工 。 如果在此后使用一个更大的 1x1 卷积层(等同于 FC 层) , GAP 后的特征便不会直接经过分类层 , 而是先进行了融合 , 并将融合的特征进行分类 。 这样可以在不影响模型推理速度的同时大大提升准确率 。
BaseNet 经过以上四个方面的改进 , 得到了 PP-LCNet 。 下表进一步说明了每个方案对结果的影响:
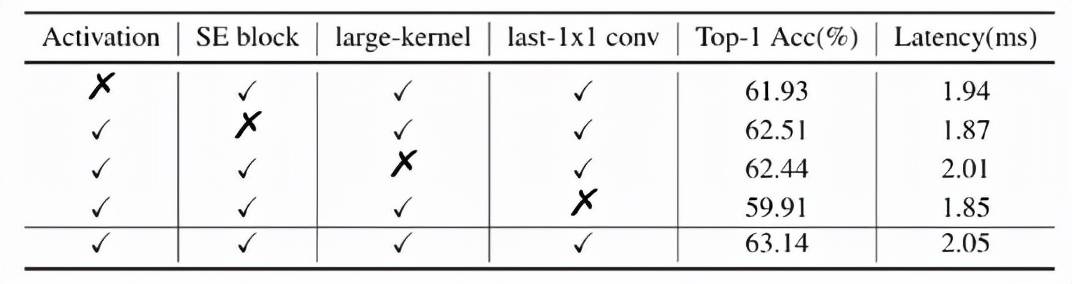
文章图片
下游任务性能惊艳提升
图像分类
图像分类我们选用了 ImageNet 数据集 , 相比目前主流的轻量级网络 , PP-LCNet 在相同精度下可以获得更快的推理速度 。 当使用百度自研的 SSLD 蒸馏策略后 , 精度进一步提升 , 在 Intel CPU 端约 5ms 的推理速度下 ImageNet 的 Top-1 Acc 竟然超过了 80% , Amazing!!!
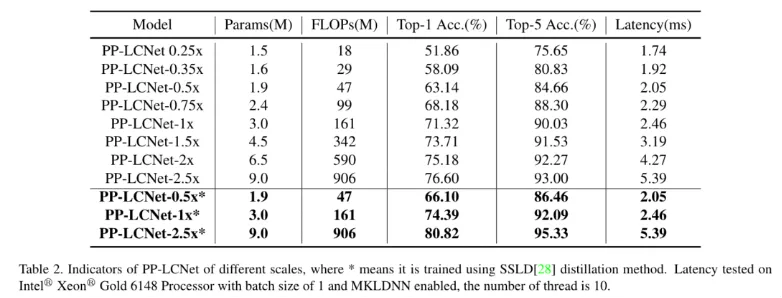
文章图片
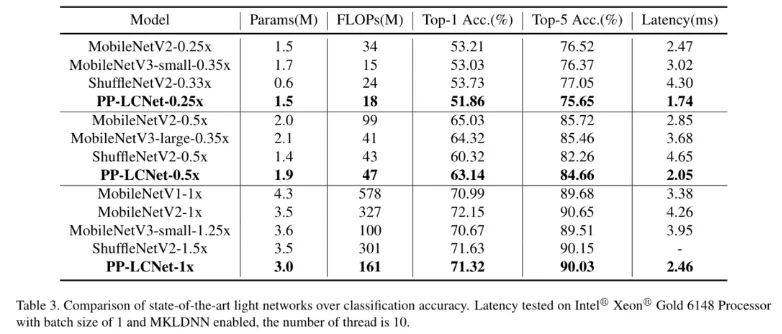
文章图片
目标检测
目标检测的方法我们选用了百度自研的 PicoDet , 该方法主打轻量级目标检测场景 。 下表展示了在 COCO 数据集上、backbone 选用 PP-LCNet 与 MobileNetV3 的结果的比较 。 无论在精度还是速度上 , PP-LCNet 的优势都非常明显 。
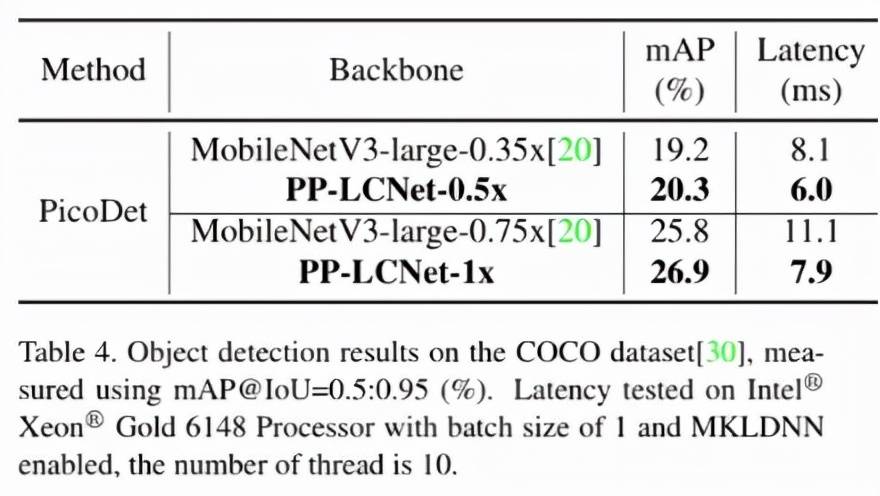
文章图片
语义分割
语义分割的方法我们选用了 DeeplabV3+ 。 下表展示了在 Cityscapes 数据集上、backbone 选用 PP-LCNet 与 MobileNetV3 的比较 。 在精度和速度方面 , PP-LCNet 的优势同样明显 。
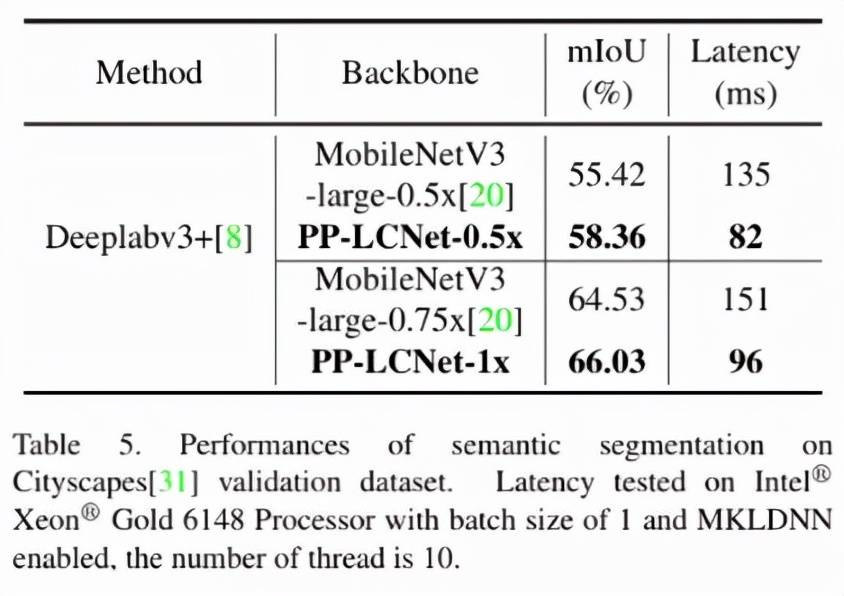
文章图片
实际拓展应用结果说明
PP-LCNet 在计算机视觉下游任务上表现很出色 , 那在真实的使用场景如何呢?本节简述其在 PP-OCR v2、PP-ShiTu 上的表现 。
在 PP-OCR v2 上 , 只将识别模型的 backbone 由 MobileNetV3 替换为 PP-LCNet 后 , 在速度更快的同时 , 精度可以进一步提升 。

文章图片
在 PP-ShiTu 中 , 将 Backbone 的 ResNet50_vd 替换为 PP-LCNet-2.5x 后 , 在 Intel-CPU 端 , 速度快 3 倍 , recall@1 基本和 ResNet50_vd 持平 。
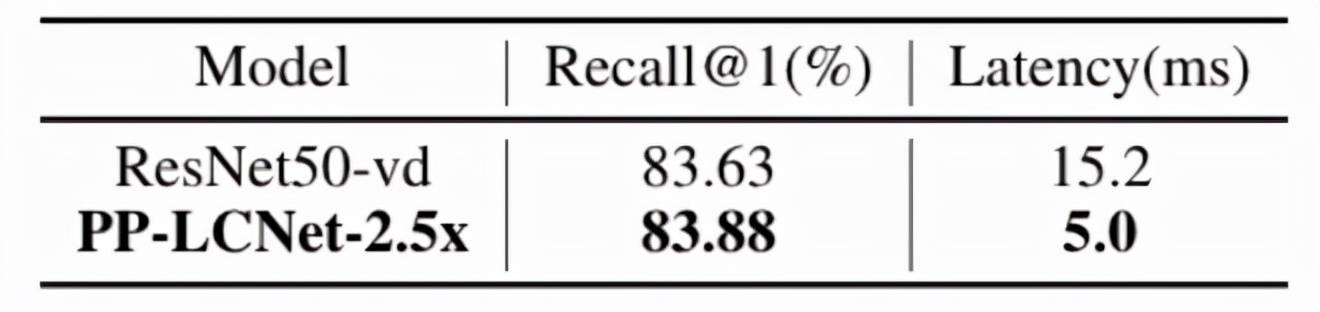
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。