该理论结果导致了一系列 「单视图方法」 , 例如 tri-training 方法等 , 最近在深度学习领域也有基于 tri-training 的半监督深度神经网络模型 。

文章图片
然而 , 半监督学习仍然需要一批有标签数据 , 例如在半监督 SVM 或基于分歧的方法中训练初始分类器 。 如果既没有 「人在环中」 的人类专家帮助、也没有充分的有标签数据 , 还有没有办法利用无标签数据呢?周志华课题组提出 , 如果有「领域知识」 , 那么可以通过机器学习和逻辑推理的结合来做 。
机器学习和逻辑推理
逻辑推理容易利用规则知识 , 机器学习容易利用数据事实 , 从人类决策来看 , 通常需要结合知识和事实以解决问题 。 研究一个能够融合机器学习和逻辑推理并使其协同工作的统一框架 , 被视为人工智能界的圣杯挑战 。
在人工智能研究的历史中 , 机器学习和逻辑推理两者基本是独立发展起来的 , 1956~1990 年是逻辑推理 + 知识工程作为人工智能主流的发展时期 , 但此时关心机器学习的人很少;1990 年之后是机器学习作为人工智能主流的发展时期 , 但此时逻辑推理已经相对冷门 。

文章图片
目前流行的逻辑推理技术通常基于一阶逻辑表示 , 而流行的机器学习一般基于特征表示 。 这两者几乎是基于完全不同的表示方式 , 难以相互转化 , 使得两者的结合极为困难 。

文章图片
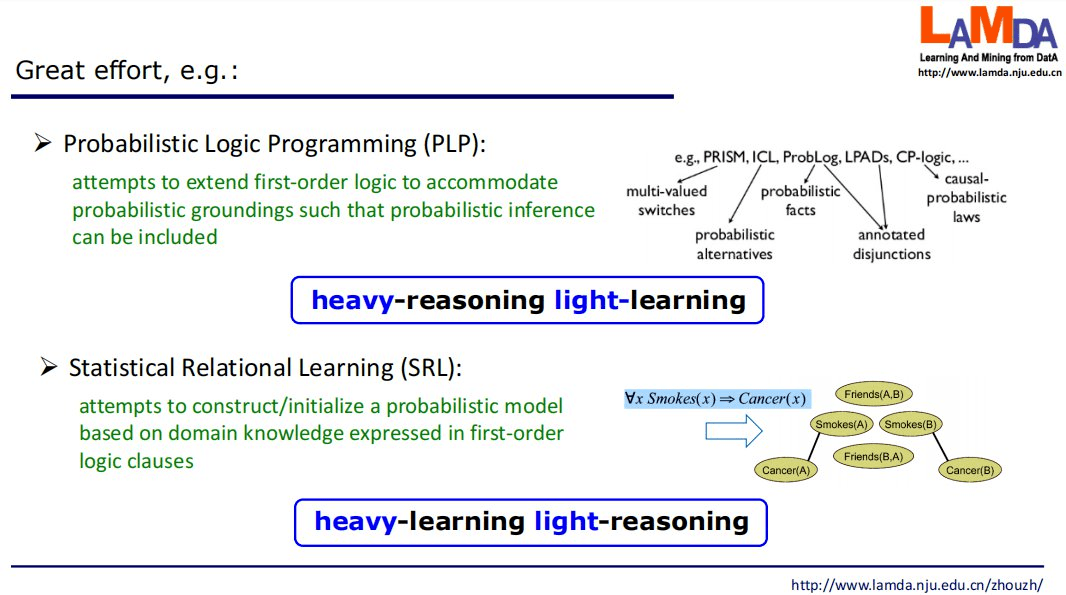
为了融合机器学习和逻辑推理 , 历史上已经有很多研究者在做努力 。 他们通常采用扩展其中一种技术来适应另一种技术的方法 。 例如 , 概率逻辑程序(PLP)尝试扩展一阶逻辑以引入概率推理 。 而统计关系学习(SRL)基于领域知识构建、初始化概率模型 。
文章图片
前者「重推理、轻学习」 , 开头引进了一点机器学习的成分 , 然后几乎完全依赖逻辑推理解决问题;后者「重学习、轻推理」 , 开头引进了一点逻辑推理的成分 , 然后几乎完全依赖机器学习解决问题 。 总是「一头重、一头轻」 , 意味着总有一端的能力没有完全发挥出来 。
这就面临一个问题 , 能不能有一个新的机制帮助我们把这两大类技术的优势都充分地发挥起来、相对均衡地「互利式地」结合逻辑推理和机器学习呢?反绎学习的提出就是为了解决这个问题 。
反绎学习(abductive learning)
反绎学习 , 是一种将机器学习和逻辑推理联系起来的新框架 。 在理解反绎学习之前 , 我们先来理解这个反绎的含义 。
在人类对现实问题的分析抽象上 , 通常有两种典型方法论:演绎 , 从一个普遍的规则开始 , 到一个有保证的特定结论 , 这就是一个从一般到特殊的过程;归纳 , 从一些特定事实开始 , 然后我们从特定的事实中总结出一般的规律 , 这就是从特殊到一般 。 定理证明可以说是演绎的典型代表 , 而机器学习是归纳的典型代表 。 反绎则与两者有所区别 , 其标准定义是首先从一个不完备的观察出发 , 然后希望得到一个关于某一个我们特别关心的集合的最可能的解释 。
周志华说他提出的反绎学习可大致理解为将演绎过程反过来嵌入到归纳过程中去 , 所以他提出 「反绎」 这个中文名字 , 而不是直接翻译为 「诱导」或「溯因」 。

特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。