文章图片
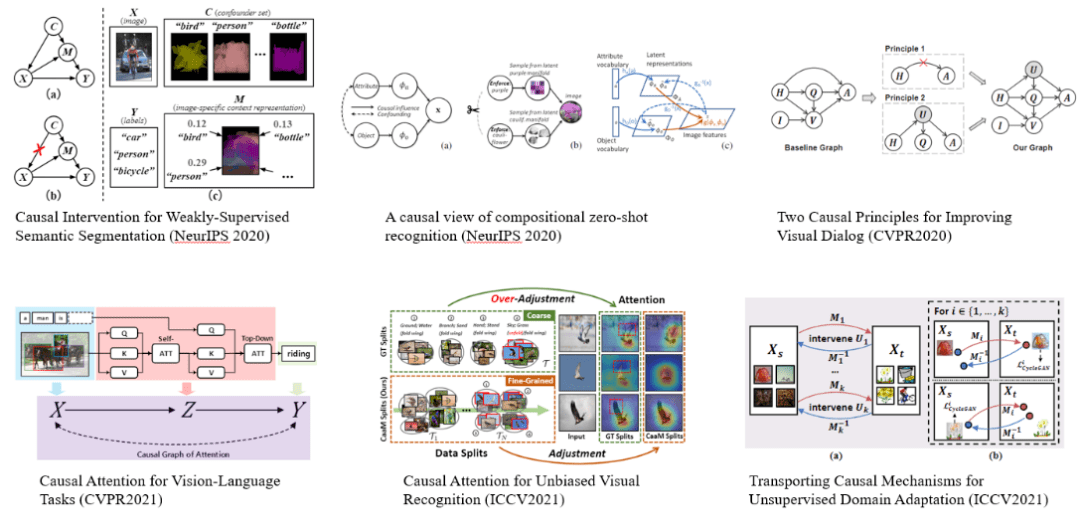
图 14. 最近的一些关于计算机视觉结合因果表达学习的工作研究 。
因果学习与知识融合
最后本人分享一下我们实验室最近在因果表达学习的一些研究进展 , 这包含了两个工作 。 第一个是计算机视觉的工作 , 研究的是如何结合因果图进行图像合成的;而第二个工作则跳脱计算机视觉的局限 , 研究医学诊疗数据下面的无偏推理问题:多轮对话下的自动医疗问诊 。 不同于现有大部分对因果表达学习的探索 , 我们这两个工作强调了如何利用外部知识或者数据中已有的结构信息 , 去辅助因果表达学习完成更加复杂的任务 , 对因果表达学习领域的未来研究具有一定的启发性 。
文章图片
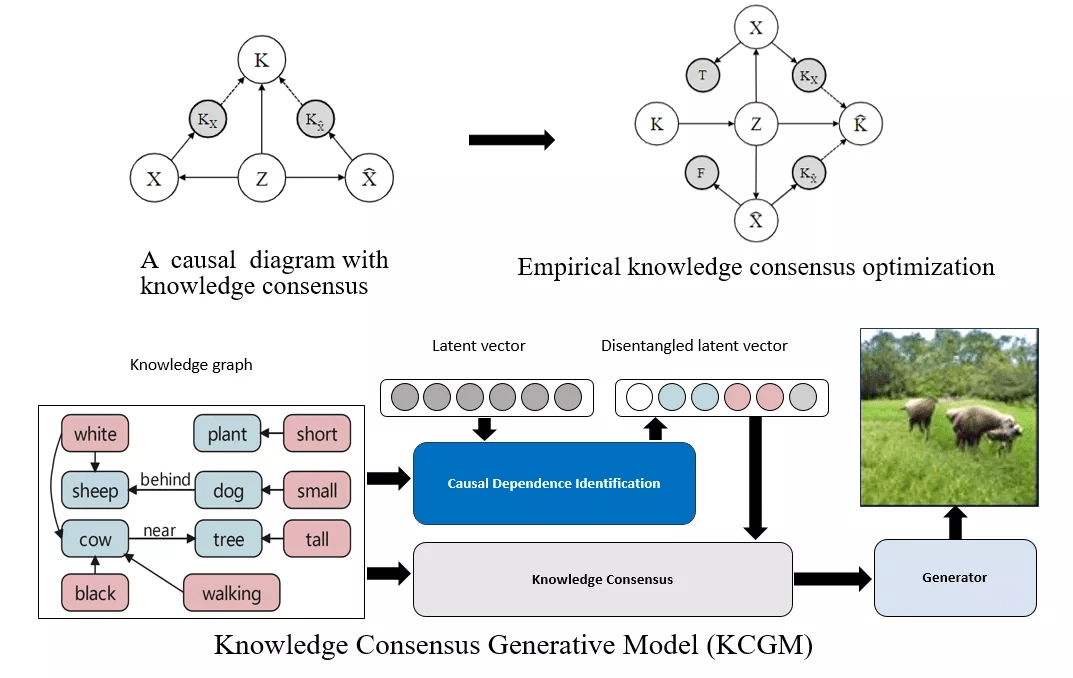
图 15. 中山大学 HCP 实验室关于表达学习生成模型结合因果图推理的研究工作 。
在第一个工作中 , 我们研究如何在给定一个语义场景图的情况下 , 实现从高层抽象语义到底层视觉数据的图像生成 。 这可以看成是场景图预测的反问题 。 而实现的过程中有两个难点:一个是如何保证生成的图像蕴含的语义信息与给定场景图的语义信息保持一致;另一个则是如何让生成图像的布局具有解耦性 , 就是修改布局的其中一部分语义不会引起整个图像的扭曲 。 而要实现这种结构上的布局解耦 , 实际上就是把相关变量看成是混淆因子来进行因果表达学习的过程 。 于是我们可以看到 , 从场景图到合成图像的生成过程 , 我们都可以用结合外部知识的因果图来表示 。 我们利用了生成对抗学习网络架构实现逼真的图像生成 , 同时采用变分自编码器的特性学习隐空间表达 , 使生成图像中对应的元素符合解耦性 。 而生成学习的目的则是在保持生成图像尽可能逼真的前提下 , 如何让生成的图像语义在结构因果关系的约束下 , 同时保持内在语义和外部知识的一致性 。 实验的结果也验证了 , 我们的方法不但能从场景图中生成语义一致的图像 , 还可以对其中的结构语义信息进行动态删减和增加 , 同时保持被编辑外的图像语义不会受到干扰和改变 。
文章图片
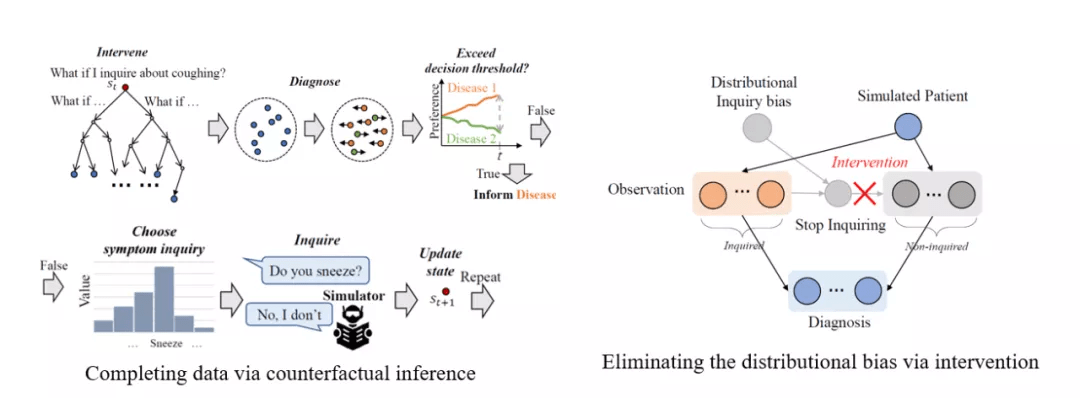
图 16. 中山大学 HCP 实验室利用因果推理技术实现可解释医疗自动诊断的研究工作 。
我们的第二个工作研究的是医疗自动诊断 , 即训练一个代理模型与患者进行动态交互问诊 , 在准确的前提下尽可能快地提前结束问诊并进行疾病的诊断 。 这本质上是一个数据挖掘建模结合机器学习的问题 , 现有的方法基本上是利用观测数据去构建一个患者模拟器 , 从而模拟交互问诊过程并对诊断代理模型进行训练 。 但这个医疗对话的模拟过程实际上使用的是观测的被动数据 , 这会造成两大因果类的偏误问题 。 第一个情况是 , 如果某一个病人的问诊记录存在从未被医生问起某种症状的时候 , 当问诊策略访问到该病人的记录进行交互训练的时候 , 患者模拟器只会返回 “不知道” 的空值回答 , 因而代理模型是无法构建针对该症状时的问诊策略的 。 这是因为该病人对于此症状的对话数据只存在于反事实世界中而没在真实世界中出现过 。 该问题被我们称为默认答案偏差 , 经常会发生在医疗诊断的数据中 , 原因非常好理解:真实世界中的医生往往都是通过先验知识去搜索最短的问诊路线 , 不存在试错的过程 。 而另外一个问题是 , 由于现存的患者模拟器是基于纯经验的 , 从因果推断的角度 , 它代表的数据往往只能反映出过去某一个观测 。 而基于这些观测训练出来的问诊代理模型 , 其策略也只会过拟合到这个观测世界中 , 而在面对医疗诊断的时候 , 这个分布查询偏差问题往往是致命的 , 因为这些信息在代理模型进行查询的过程中往往会带来数据偏见 , 使得最后的诊断结果产生错误 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。