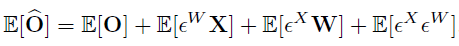
文章图片
在实现过程中 , 误差的期望值可以通过校验数据集来计算 , 然后在网络层的 bias 参数中去修正 。
混合比特量化
不同的 transformer 网络层有不同的数据分布 , 因为有不同的量化「敏感度」 。 研究者提出了混合精度量化 , 对于更加「敏感」的网络层分配更多的比特宽度 。
在论文中 , 研究者提出使用 MSA 模块中注意力层特征和 MLP 中输出特征矩阵的核范数来作为度量网络层「敏感度」的方法 。 与 HAWQ-V2 中的方法类似 , 他们使用了一种帕累托最优的方式来决定网络层的量化比特 。 该方法的主要思想是对每个候选比特组合进行排序 , 具体的计算方式如下所示:
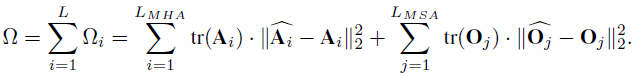
文章图片
给定一个目标模型大小 , 会对所有的候选比特组合进行排序 , 并寻找值最小的候选比特组合作为最终的混合比特量化方案 。
实验验证
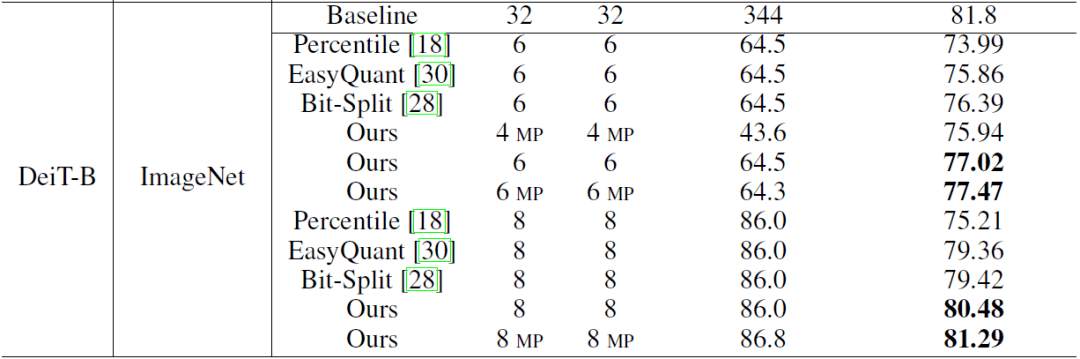
研究者首先在图像分类任务上对后训练量化算法进行了验证 。 从下表可以看出 , 在 ViT(DeiT)经典 transformer 模型上 , 论文的量化算法均优于之前的卷积神经网络量化算法【1】【2】 。 例如 , 在 ImageNet 数据集上 , 量化 Deit-B 模型也取得了 81.29% 的 Top-1 准确率 。
文章图片
图像分类任务上的后训练量化结果 。
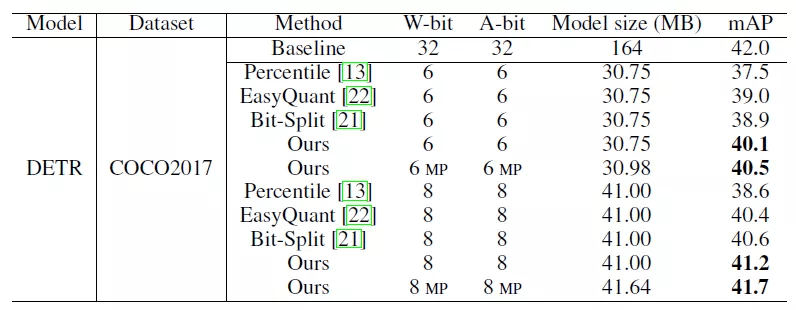
研究者还将后训练量化算法应用于目标检测任务中 , 其中在 COCO2017 数据集上 , 对 DETR 进行量化 , 8bit 模型的性能可以达到 41.7 mAP , 接近全精度模型的性能 。
文章图片
目标检测任务上的后训练量化结果 。
论文 2
《Towards Efficient Post-training Quantization of Pre-trained Language Models》

文章图片
论文链接:https://arxiv.org/pdf/2109.15082.pdf
方法概述
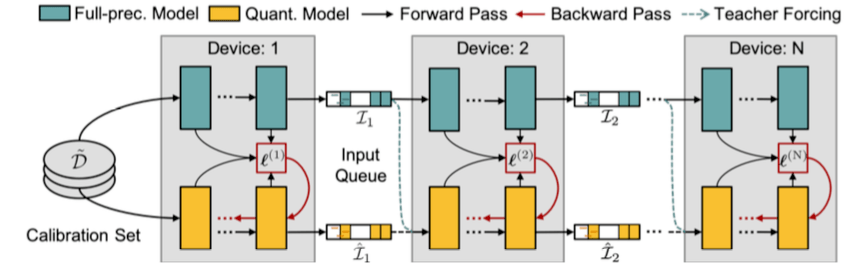
下图为并行蒸馏下的模型后量化总体框架:
文章图片
模块化重构误差最小化
由于 Transformer-based 的预训练语言模型通常含有多个线性层耦合在一起 , 如果采用现有的逐层重构误差优化的方法【3】 , 作者发现很容易陷入局部最优解 。 为了考虑多个线性层内部的交互 , 如上图所示 , 研究者把预训练语言模型切分成多个模块 , 每个模块含有多个 Transformer 层 。
因此该方法聚焦于逐个重构模块化的量化误差 , 即最小化全精度网络模块(教师模型)的输出与量化后模型模块(学生网络)的输出之间的平方损失:
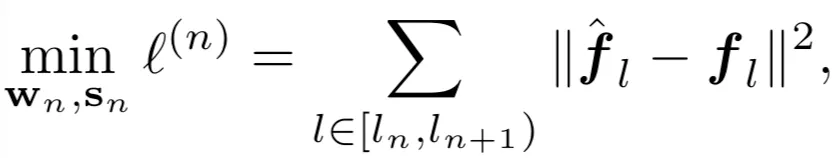
文章图片
并行知识蒸馏训练
与逐个模块化重构量化误差不同 , 后量化还可以并行化训练 。 研究者把每个切分后的模块可以放在不同的 GPU 上 , 在不同模块之间设置输入缓冲池(input queue)
文章图片
来收集上一个模块的输出 , 同时为下一个模块的输入做准备 。 不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练 , 无需等待其前继模块 。 因此 , 该设计可以使并行训练 , 并且实现接近理论加速比 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。