在第二阶段 , 高性能 RL 算法通过与环境交互来收集数据并找到控制策略 , 如图 1a、b 所示 。 该研究使用的模拟器具有足够的物理保真度来描述等离子体形状和电流的演变 , 同时保持足够低的计算成本来学习 。 具体来说 , 该研究基于自由边界等离子体演化(free-boundary plasma-evolution )模型 , 对等离子体状态在极向场线圈电压的影响下的演化进行建模 。
RL 算法使用收集到的模拟器数据来找到关于指定奖励函数的最优策略 。 由于演化等离子体状态的计算要求 , 模拟器的数据速率明显低于典型 RL 环境的数据速率 。 该研究通过最大后验策略优化 (MPO) 来克服数据不足问题 。 MPO 支持跨分布式并行流的数据收集 , 并以高效的方式进行学习 。
在第三阶段 , 控制策略与相关的实验控制目标绑定到一个可执行文件中 , 使用量身定制的编译器(10 kHz 实时控制) , 最大限度地减少依赖性并消除不必要的计算 。 这个可执行文件是由托卡马克配置变量(TCV)控制框架加载的(图 1d) 。 每个实验都从标准的等离子体形成程序(plasma-formation procedures)开始 , 其中传统控制器维持等离子体的位置和总电流 。 在预定时间里 , 称为「handover」 , 控制切换到控制策略 , 然后启动 19 个 TCV 控制线圈 , 将等离子体形状和电流转换为所需的目标 。 训练完成后将不会进一步调整网络权值 , 换句话说 , 从模拟到硬件实现了零样本迁移 。
基本功能演示
该研究在 TCV 实验中展示了所提架构在控制目标上的能力 。 首先他们展示了对等离子体平衡基本质量的精确控制 。 控制策略性能如图 2 所示 。 所有任务都成功执行 , 跟踪精度低于期望的阈值 。 结果表明 RL 体系架构能够在放电实验的所有相关阶段进行精确的等离子体控制 。
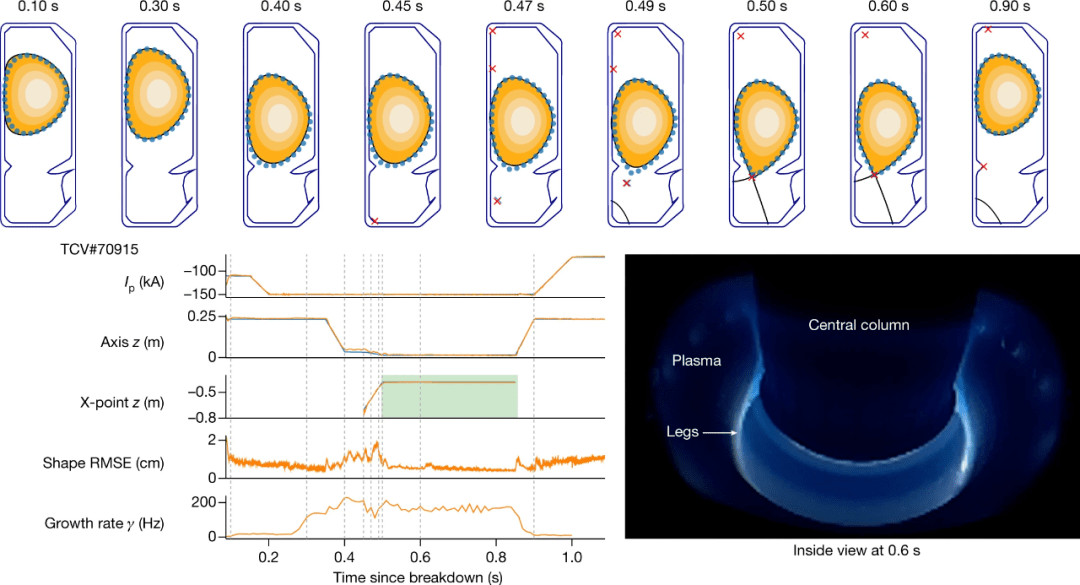
文章图片
图 2:等离子体电流、垂直稳定性、位置与形状控制的演示 。
控制演示
接下来 , 该研究展示了所提架构为科学研究生成复杂配置的能力 。 结果如图 3 所示:
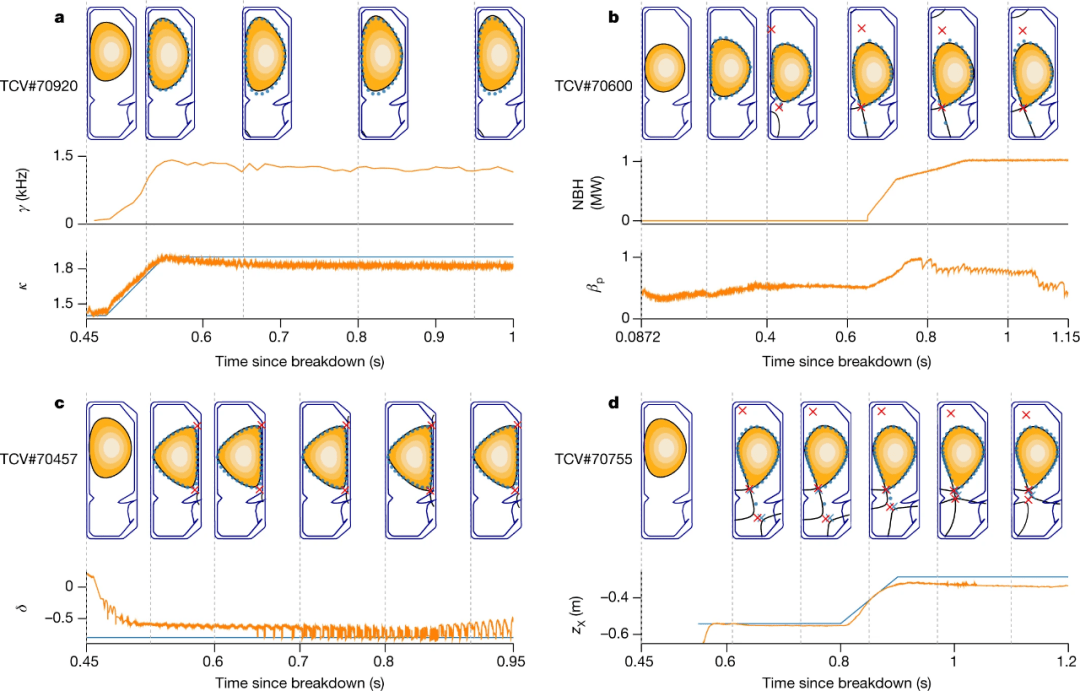
文章图片
图 3 控制演示 。
全新多域等离子体演示
最后展示了架构在探索全新等离子配置方面的强大功能 。 DeepMind 测试了「液滴」(droplets)的控制 , 这是一种在容器内部同时存在两个独立等离子体的配置 。 通过提出的方法 , DeepMind 简单地调整了模拟切换状态 , 以考虑来自单轴等离子体的不同切换条件 , 并定义一个奖励函数以保持每个液滴组件的位置稳定 , 同时增加域等离子体电流 。
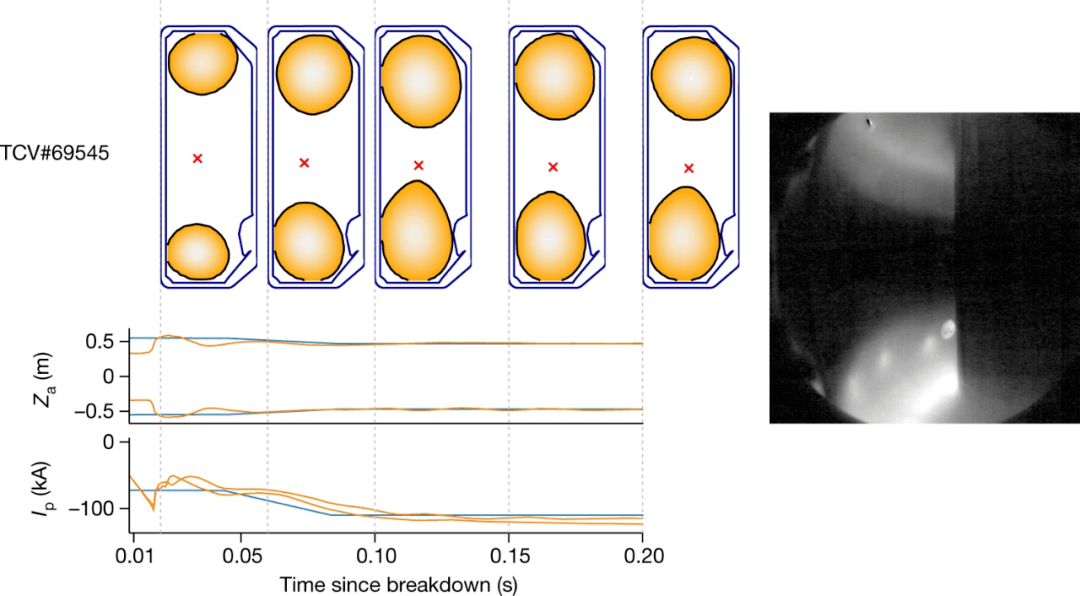
文章图片
图 4:整个 200 毫米控制窗口内对 TCV 上两个独立液滴的持续控制演示 。
【史上首次,强化学习算法控制核聚变登上Nature:DeepMind让人造太阳向前一大步】未来展望
总而言之 , 随着聚变反应堆变得越来越大 , 与 DeepMind 展开合作或许是最关键的 。 尽管物理学家已经很好地掌握了如何通过传统方法控制小型托卡马克中的等离子体 , 但随着科学家们尝试令核电站规模的版本可行 , 挑战只会更多 。 该领域正取得缓慢但稳定的进展 。
上周 , 位于英国牛津郡的欧洲联合环状反应堆(JET)项目取得了突破 , 创造了从聚变实验中提取能量的新纪录 , 在 5 秒时间内产生了 59 兆焦耳的能量 。 与此同时 , 位于法国的国际热核聚变实验反应堆(ITER)国际合作项目正在建设当中 , 预计将于 2025 年启动并成为世界上最大的实验性聚变反应堆 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。