在预训练阶段 , 研究员使用了自回归模型作为预训练任务来训练 NüWA , 其中 VQ-GAN 编码器将图像和视频转换为相应的视觉标记 , 作为预训练数据的一部分 。 在推理阶段 , VQ-GAN 解码器会基于预测的离散视觉标记重建图像或视频 。
NüWA 还引入了三维稀疏注意力(3D Nearby Attention , 3DNA)机制来应对 3D 数据的特性 , 可同时支持编码器和解码器的稀疏关注 。 也就是说 , 在生成特定图像的一部分或者一个视频帧时 , NüWA 不仅会看到已经生成的历史信息 , 还会关注与其条件所对应位置的信息 , 比如 , 在由视频草图生成视频的过程中 , 生成第二帧时 , 模型就会考虑第二帧草图对应的位置是什么 , 然后按照草图的变化生成满足草图变化的视频 , 这就是编码器和解码器的同时稀疏 。 而此前的工作通常只是一维或二维的稀疏关注 , 而且只在编码器稀疏 , 或只在解码器稀疏 。 通过使用 3DNA 机制 , NüWA 的计算复杂度得到了简化 , 提升了计算效率 。

文章图片
图1:NüWA 基于 3D 编码-解码架构
为了支持文本、图片、视频这些多模态任务的创建 , 跨越不同领域数据的鸿沟 , 研究员采用了逐步训练的方式 , 在预训练中使用不同类型的训练数据 。 首先训练文本-图片任务和图片-视频任务 , 待任务稳定后 , 再加入文本-视频的数据进行联合训练 , 而且研究员们还使用了视频完成任务 , 根据给定的部分视频作为输入生成后续视频 , 使得 NüWA 拥有强大的零样本视觉内容生成与编辑能力 , 实现图像、视频内容的增、删、改操作 , 甚至可以对视频的未来帧进行可控调整 。
微软亚洲研究院高级研究员段楠表示 , “NüWA 是第一个多模态预训练模型 。 我们希望 NüWA 可以实现真实世界的视频生成 , 但在训练过程中模型会产生大量的‘中间变量’ , 消耗巨大的显存、计算等资源 。 因此 , NüWA 团队与系统组的同事们联手协作 , 为 NüWA 在系统架构上设置了多种并行机制 , 如张量并行、管道并行和数据并行 , 使得我们的跨模态训练成为可能 。 ”
NüWA 覆盖了11个数据集和11种评估指标 。 在文本到图像生成的弗雷切特起始距离(Frechet Inception Distance, FID)指标上 , NüWA 的表现超过了 DALL-E 和 CogView , 在视频生成的 FVD 指标上超越了 CCVS , 均取得了当前 SOTA 结果 。 其中 , 测试结果如下(更多 NüWA 在不同数据集和评估指标中的测试结果 , 请点击阅读原文 , 查看论文细节):
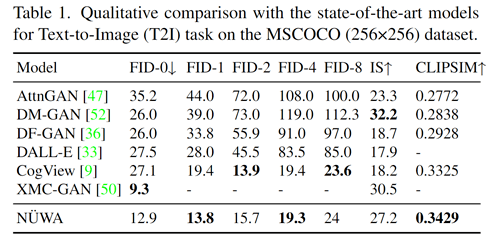
文章图片
表1:文本到图像任务测试结果
NüWA-LIP:让视觉编辑更精细
NüWA 模型已基本包含了视觉创作的核心流程 , 可在一定程度上辅助创作者提升效率 , 但在实际创作中 , 创作者还有很多多样且高质量的需求 。 为此 , 微软亚洲研究院的研究员们在 NüWA 的基础之上更新迭代 , 于近日提出了NüWA-LIP 模型 , 并且在视觉领域的典型任务——缺陷图像修复中取得了新突破 。
尽管此前也有方法完成了类似的图像修复 , 但是模型的创作却比较随意 , 无法符合创作者的意愿 , 而NüWA LIP 几乎可以按照给定的自然语言指令修复、补全成人们肉眼可接受的图像 。 下面 , 让我们直观感受一下 NüWA-LIP 神奇的图像修复效果 。

文章图片
图2:在图像编辑任务上 , NüWA-LIP 展现出优秀的性能
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。