Ithaca 是在最大的希腊铭文数字数据集上训练完成 , 该数据集由帕卡德人文学院 (PHI)提供 , 这是一个非营利基金会 , 成立于 1987 年 , 该机构旨在为基础研究创建工具人文学 。 通常来讲 , 自然语言处理模型使用单词进行训练 , 它们在句子中出现的顺序以及单词之间的关系可以提供额外的上下文和含义 。 然而 Ithaca 的铭文损坏严重 , 丢失了大部分文本块 。 为了确保模型有效 , 该研究使用单词和单个字符作为输入 。 模型核心为稀疏自注意力机制 , 用来并行计算这两个输入(单词和单个字符) 。
文章图片
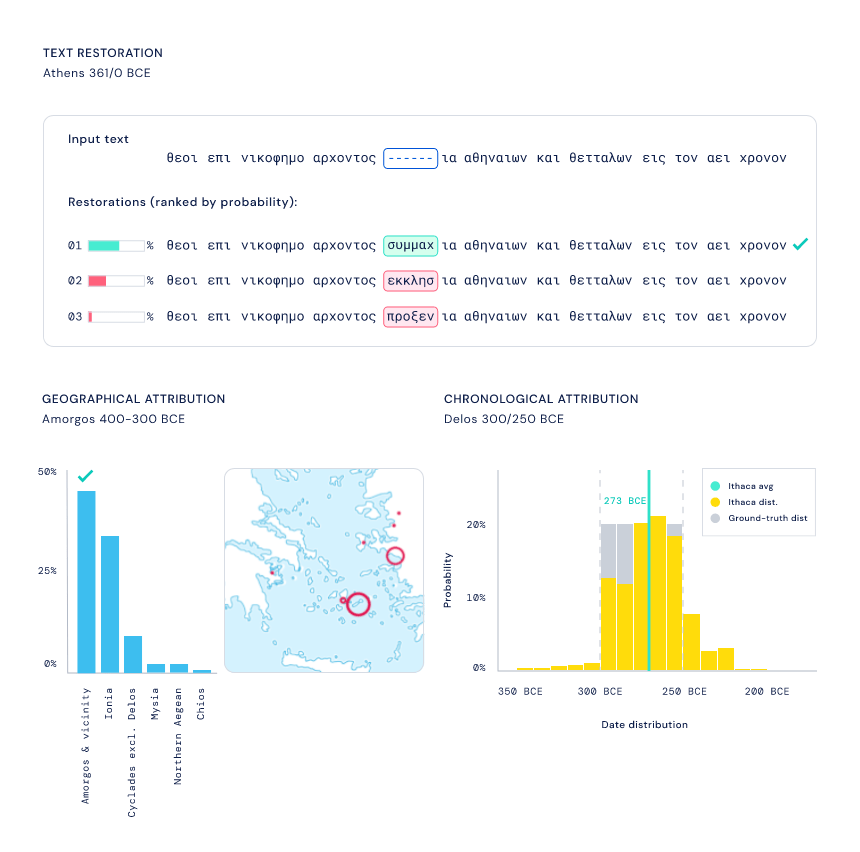
图 3:Ithaca 的输出
为了最大限度地发挥 Ithaca 作为研究工具的价值 , 该研究还创建了许多视觉辅助工具 , 以确保 Ithaca 的研究结果易于被历史学家解读:
- 恢复假设:Ithaca 为文本修复任务生成几个预测假设 , 供历史学家利用自身专业知识进行选择;
- 地理归属:Ithaca 通过为历史学家提供所有可能预测的概率分布来显示其不确定性 , 而不仅仅是单个输出 。 因此 , Ithaca 返回代表其确定性水平的 84 个不同古代区域的概率 。 可以在地图上将这些结果可视化 , 以阐明古代世界可能存在的潜在地理联系;
- 时间归属:当需要确定一篇文献的年代时 , Ithaca 会产生从公元前 800 年到公元 800 年预测日期分布 , 这可以使历史学家了解模型对特定日期范围的可信度 , 提供有价值的历史见解;
- 显着图:为了将结果传达给历史学家 , Ithaca 使用计算机视觉中常用的一种技术来识别哪些输入序列对预测的贡献最大 , 输出以不同颜色强度突出 Ithaca 预测缺失文本、地点和日期的单词 。

文章图片
数据集与模型
为了训练 Ithaca , 该研究开发了一个 pipeline 来检索未处理的 PHI 数据集 , 该数据集由 178,551 个铭文转录文本组成 。 每个 PHI 铭文都被分配了一个唯一的数字 ID , 并标有与写作地点和时间相关的元数据 。 PHI 共列出了 84 个古代区域 , 而年代信息以多种格式记录 , 从历史时代到精确的年份间隔 , 用多种语言编写 。 PHI 数据集在经过处理和过滤后 , 该研究得到新数据集 I.PHI , 据了解这是最大的机器可操作铭文多任务数据集 , 包含 78,608 个铭文 。
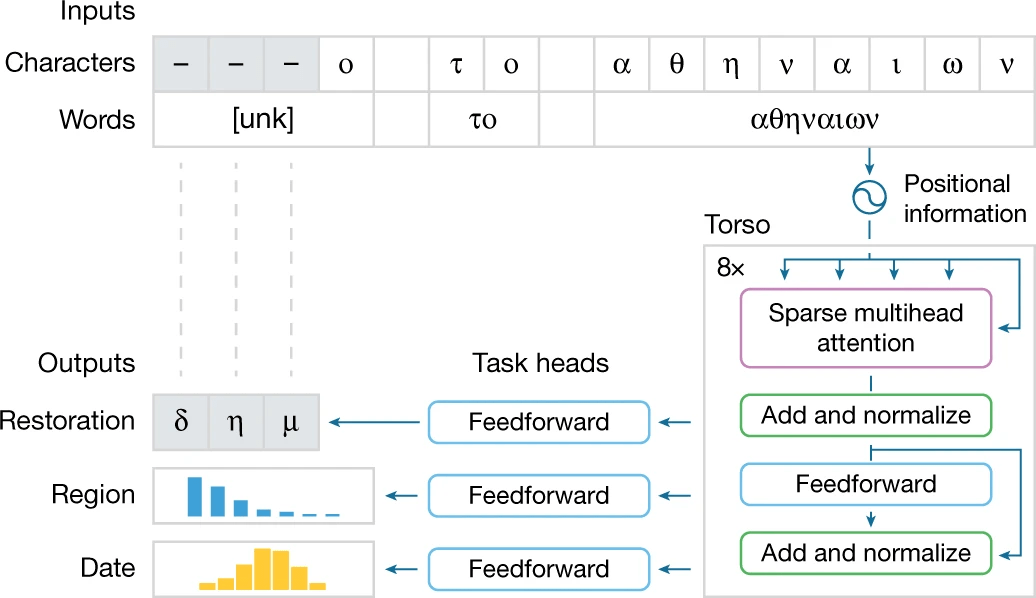
由于部分铭文文字丢失 , 该研究将字符和单词作为输入 , 用特殊符号 [unk] 表示损坏、丢失或未知的单词 。 接下来 , 为了实现大规模处理 , Ithaca 的主干是基于 transformer 的神经网络架构 , 它使用注意力机制来衡量输入的不同部分(如字符、单词)对模型决策的影响过程 。 通过将输入字符和单词表示与它们的顺序位置信息连接起来 , 注意力机制得到输入文本的每个部分的位置 。
Ithaca 的主干由堆叠的 transformer 块组成:每个块输出一系列处理后的表示 , 其长度等于输入字符的数量 , 每个块的输出成为下一个块的输入 。 主干的最终输出被传递给三个不同的任务头 , 分别处理恢复、地理归属和时间归属 。 每个头都由一个浅层前馈神经网络组成 , 专门针对每个任务进行训练 。 在图 2 所示的例子中 , 恢复头预测了三个丢失的字符;地理归属头将铭文分为 84 个区域 , 并且按时间顺序的归属头将其追溯到公元前 800 年至公元 800 年之间 。
文章图片
该短语的前三个字符被隐藏 , Ithaca 提出了修复建议 , 同时 , Ithaca 还预测了铭文的地区和日期 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。