简介:数据湖概念日益火热 , 本文由阿里云开源大数据 OLAP 团队和 StarRocks 数据湖分析团队共同为大家介绍“ StarRocks 极速数据湖分析 ”背后的原理 。
StarRocks 是一个强大的数据分析系统 , 主要宗旨是为用户提供极速、统一并且易用的数据分析能力 , 以帮助用户通过更小的使用成本来更快的洞察数据的价值 。 通过精简的架构、高效的向量化引擎以及全新设计的基于成本的优化器(CBO) , StarRocks 的分析性能(尤其是多表 JOIN 查询)得以远超同类产品 。
为了能够满足更多用户对于极速分析数据的需求 , 同时让 StarRocks 强大的分析能力应用在更加广泛的数据集上 , 阿里云开源大数据 OLAP 团队联合社区一起增强 StarRocks的数据湖分析能力 。 使其不仅能够分析存储在 StarRocks 本地的数据 , 还能够以同样出色的表现分析存储在 Apache Hive、Apache Iceberg 和 Apache Hudi 等开源数据湖或数据仓库的数据 。
本文将重点介绍 StarRocks 极速数据湖分析能力背后的技术内幕 , 性能表现以及未来的规划 。
一、整体架构 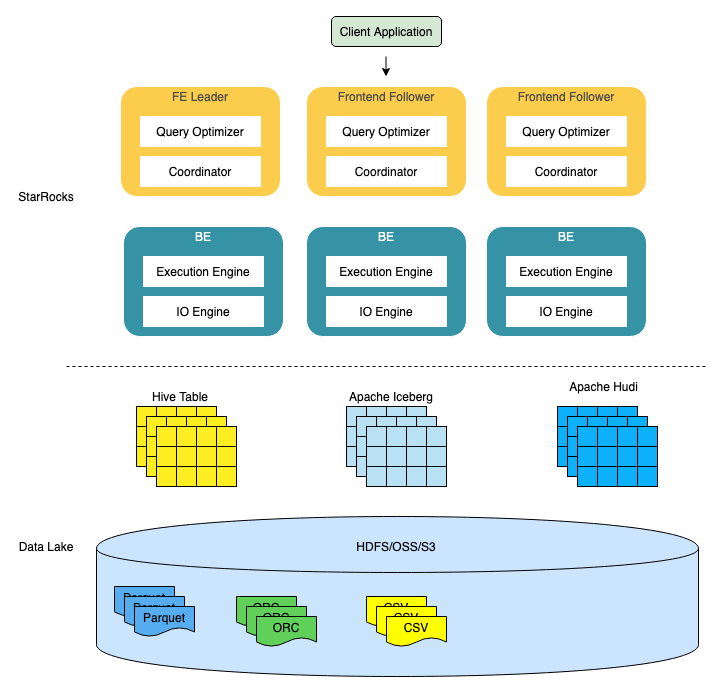
文章图片
在数据湖分析的场景中 , StarRocks 主要负责数据的计算分析 , 而数据湖则主要负责数据的存储、组织和维护 。 上图描绘了由 StarRocks 和数据湖所构成的完成的技术栈 。
StarRocks 的架构非常简洁 , 整个系统的核心只有 FE(Frontend)、BE(Backend)两类进程 , 不依赖任何外部组件 , 方便部署与维护 。 其中 FE 主要负责解析查询语句(SQL) , 优化查询以及查询的调度 , 而 BE 则主要负责从数据湖中读取数据 , 并完成一系列的 Filter 和 Aggregate 等操作 。
数据湖本身是一类技术概念的集合 , 常见的数据湖通常包含 Table Format、File Format 和 Storage 三大模块 。 其中 Table Format 是数据湖的“UI” , 其主要作用是组织结构化、半结构化 , 甚至是非结构化的数据 , 使其得以存储在像 HDFS 这样的分布式文件系统或者像 OSS 和 S3 这样的对象存储中 , 并且对外暴露表结构的相关语义 。 Table Format 包含两大流派 , 一种是将元数据组织成一系列文件 , 并同实际数据一同存储在分布式文件系统或对象存储中 , 例如 Apache Iceberg、Apache Hudi 和 Delta Lake 都属于这种方式;还有一种是使用定制的 metadata service 来单独存放元数据 , 例如 StarRocks 本地表 , Snowflake 和 Apache Hive 都是这种方式 。
File Format 的主要作用是给数据单元提供一种便于高效检索和高效压缩的表达方式 , 目前常见的开源文件格式有列式的 Apache Parquet 和 Apache ORC , 行式的 Apache Avro 等 。
Storage 是数据湖存储数据的模块 , 目前数据湖最常使用的 Storage 主要是分布式文件系统 HDFS , 对象存储 OSS 和 S3 等 。
FE
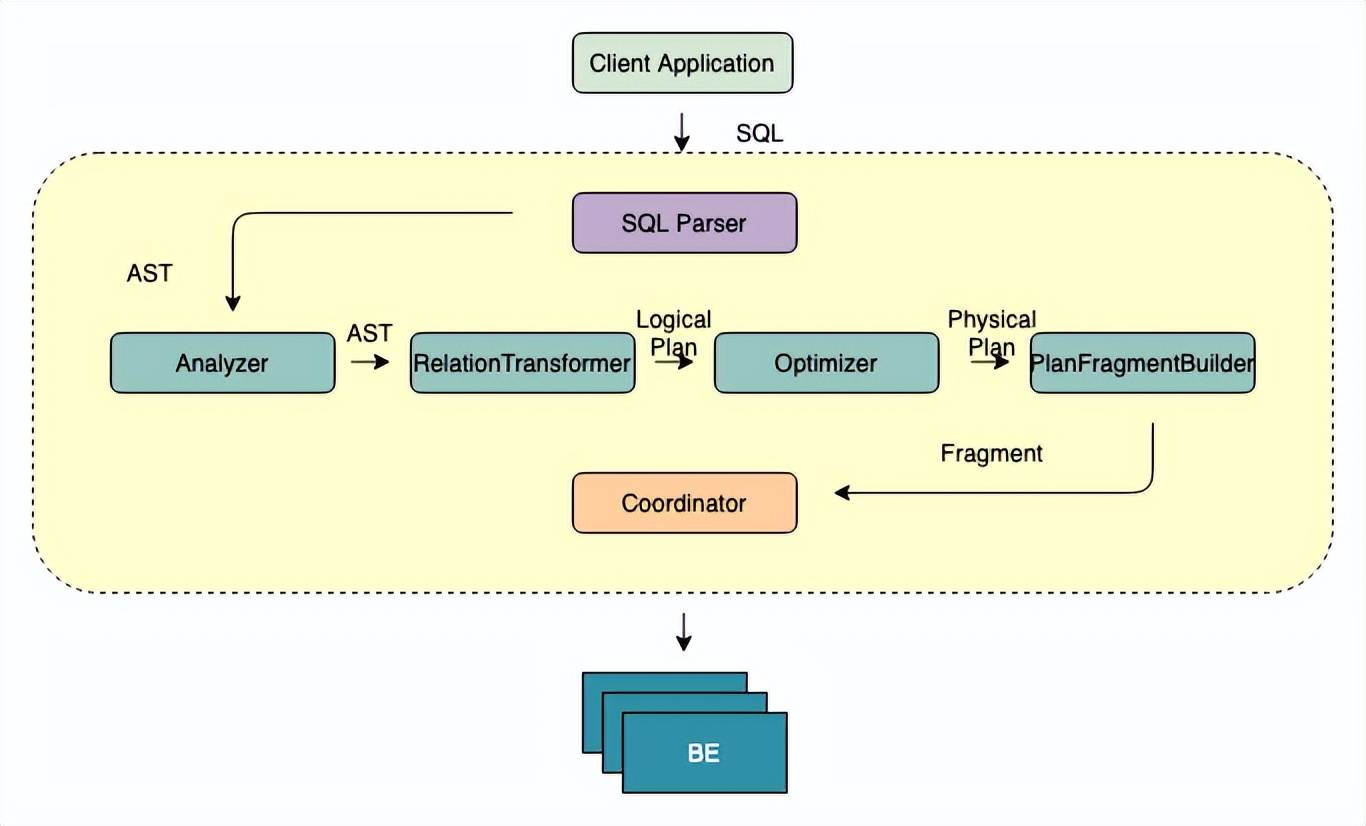
文章图片
FE 的主要作用将 SQL 语句转换成 BE 能够认识的 Fragment , 如果把 BE 集群当成一个分布式的线程池的话 , 那么 Fragment 就是线程池中的 Task 。 从 SQL 文本到分布式物理执行计划 , FE 的主要工作需要经过以下几个步骤:
- SQL Parse: 将 SQL 文本转换成一个 AST(抽象语法树)
- SQL Analyze:基于 AST 进行语法和语义分析
- SQL Logical Plan: 将 AST 转换成逻辑计划
- SQL Optimize:基于关系代数 , 统计信息 , Cost 模型对 逻辑计划进行重写 , 转换 , 选择出 Cost “最低” 的物理执行计划
- 生成 Plan Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Plan Fragment 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。