机器之心报道
编辑:陈萍、小舟
DeepMind 提出的 Rainbow 算法 , 可以让 AI 玩 Atari 游戏的水平提升一大截 , 但该算法计算成本非常高 , 一个主要原因是学术研究发布的标准通常是需要在大型基准测试上评估新算法 。 来自谷歌的研究者通过添加和移除不同组件 , 在有限的计算预算、中小型环境下 , 以小规模实验得到与 Rainbow 算法一致的结果 。人们普遍认为 , 将传统强化学习与深度神经网络结合的深度强化学习 , 始于 DQN 算法的开创性发布 。 DQN 的论文展示了这种组合的巨大潜力 , 表明它可以产生玩 Atari 2600 游戏的有效智能体 。 之后有多种方法改进了原始 DQN , 而 Rainbow 算法结合了许多最新进展 , 在 ALE 基准测试上实现了 SOTA 的性能 。 然而这一进展带来了非常高的计算成本 , 拥有充足计算资源的和没有计算资源之间的差距被进一步拉大 。
在 ICML 2021 的一篇论文《Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research》中 , 研究者首先讨论了与 Rainbow 算法相关的计算成本 。 研究者探讨了通过结合多种算法组件 , 以小规模实验得到与 Rainbow 算法一致的结果 , 并将该想法进一步推广到在较小的计算预算上进行的研究如何提供有价值的科学见解 。

文章图片
论文地址:https://arxiv.org/abs/2011.14826
Rainbow 计算成本高的一个主要原因是学术研究发布的标准通常是需要在大型基准测试(例如 ALE , 其中包含 57 款强化学习智能体能够学会玩 Atari 2600 游戏)上评估新算法 。 通常使用 Tesla P100 GPU 训练模型学会玩一个游戏大约需要五天时间 。 此外 , 如果想要建立有意义的置信边界 , 通常至少执行 5 次运行 。
因此 , 在全套 57 款游戏上训练 Rainbow 需要大约 34,200 个 GPU hour(约 1425 天)才能提供令人信服的性能实验数据 。 这样的实验只有能够在多个 GPU 上并行训练时才可行 , 这使得较小的研究小组望而却步 。
Rainbow 算法
与原始 Rainbow 算法的论文一样 , 在 ICML 2021 的这篇论文中 , 研究者评估了在原始 DQN 算法中添加以下组件的效果:双 Q 学习(double Q-learning)、优先经验回放(prioritized experience replay , PER)、竞争网络、多步学习、分布式强化学习和嘈杂网络 。
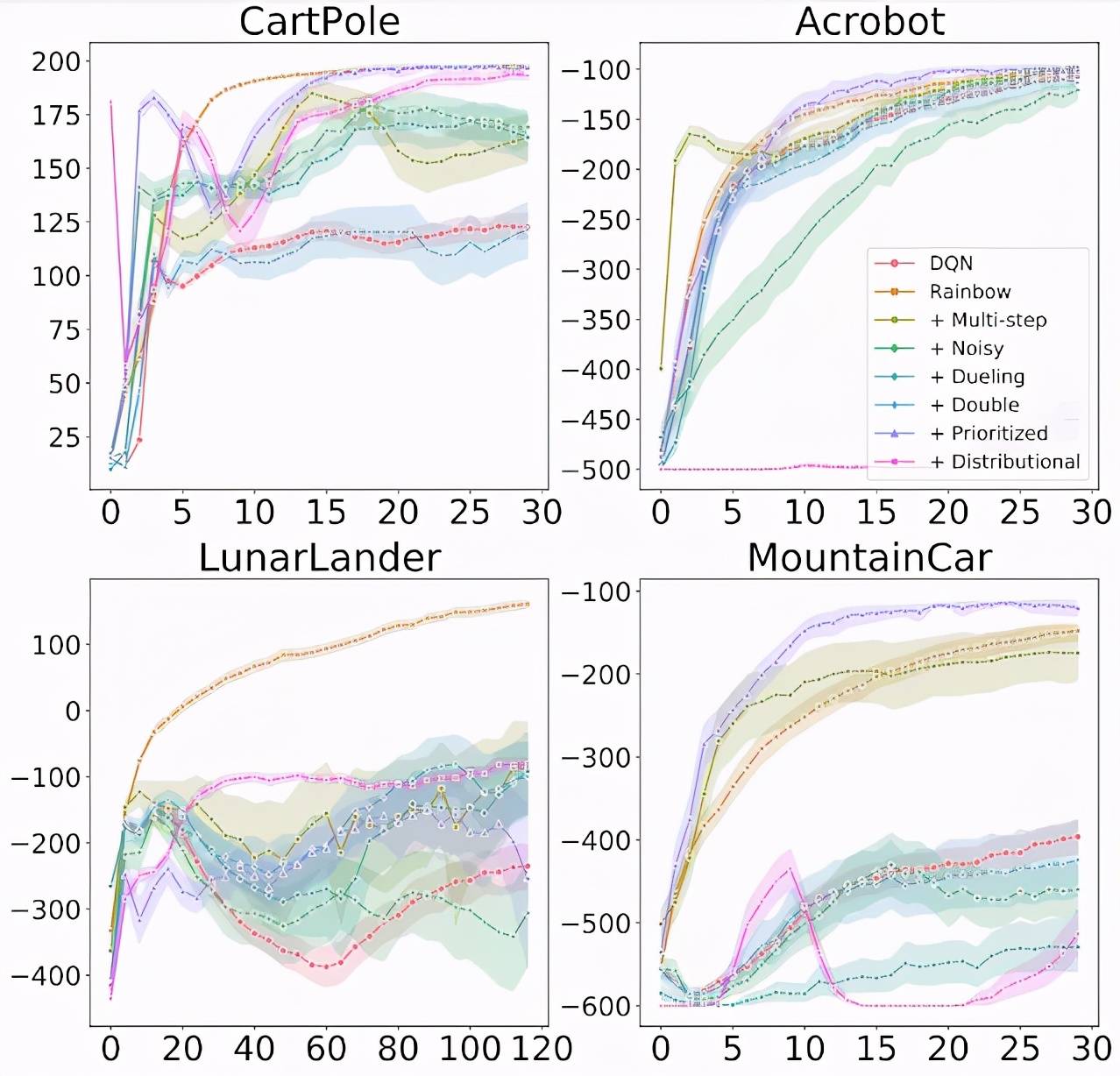
该研究在四个经典控制环境中进行评估 。 需要注意的是 , 相比于 ALE 游戏需要 5 天 , 这些环境在 10-20 分钟内就可以完成完全训练:
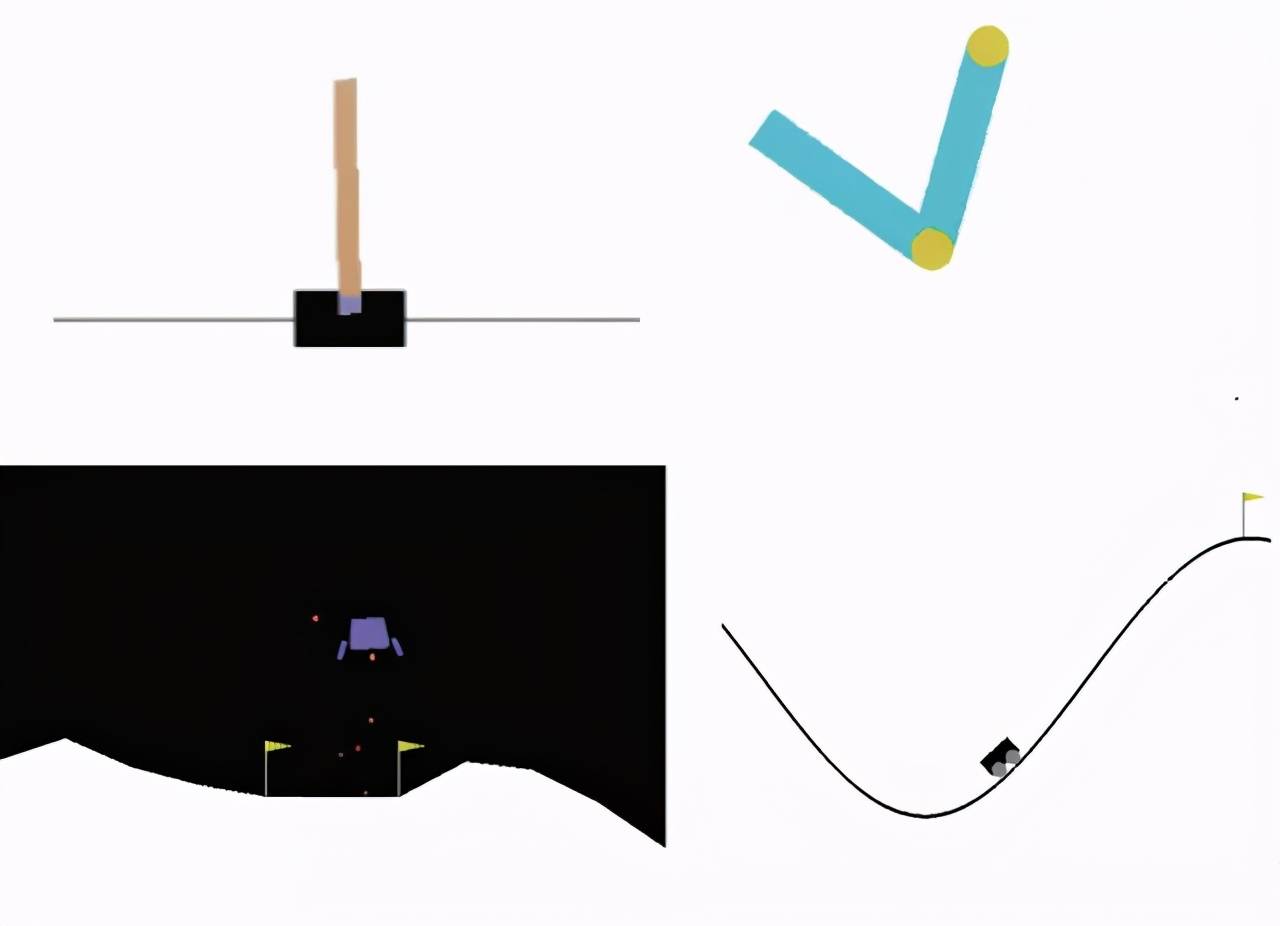
文章图片
左上:在 CartPole 中 , 游戏任务是智能体通过左右移动平衡推车上的一根杆子;右上:在 Acrobot 中 , 有两个杠杆和两个连接点 , 智能体需要向两个杠杆之间的连接点施加力以抬高下面的杠杆使其高于某个高度要求 。 左下:在 LunarLander 中 , 智能体的任务是将飞船降落在两个旗帜之间;右下:在 MountainCar 中 , 智能体需要在两座山丘之间借助一定的动力将车开到右边的山顶 。
研究者探究了将每个组件单独添加到 DQN 以及从完整 Rainbow 算法中删除每个组件的效果 , 并发现总的来说每一个算法组件的添加都确实改进了基础 DQN 的学习效果 。 然而 , 该研究也发现了一些重要的差异 , 例如通常被认为能起到改进作用的分布式 RL 自身并不总是能够产生改进 。 实际上 , 与 Rainbow 论文中的 ALE 结果相反 , 在经典控制环境中 , 分布式 RL 仅在与其他组件结合时才会产生改进 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。