文章图片
【训练|训练Rainbow算法需要1425个GPU Day?谷歌说强化学习可以降低计算成本】上图显示了在 4 个经典控制环境中 , 向 DQN 添加不同组件时的训练进度 。 x 轴为训练 step , y 轴为性能(越高越好) 。
文章图片
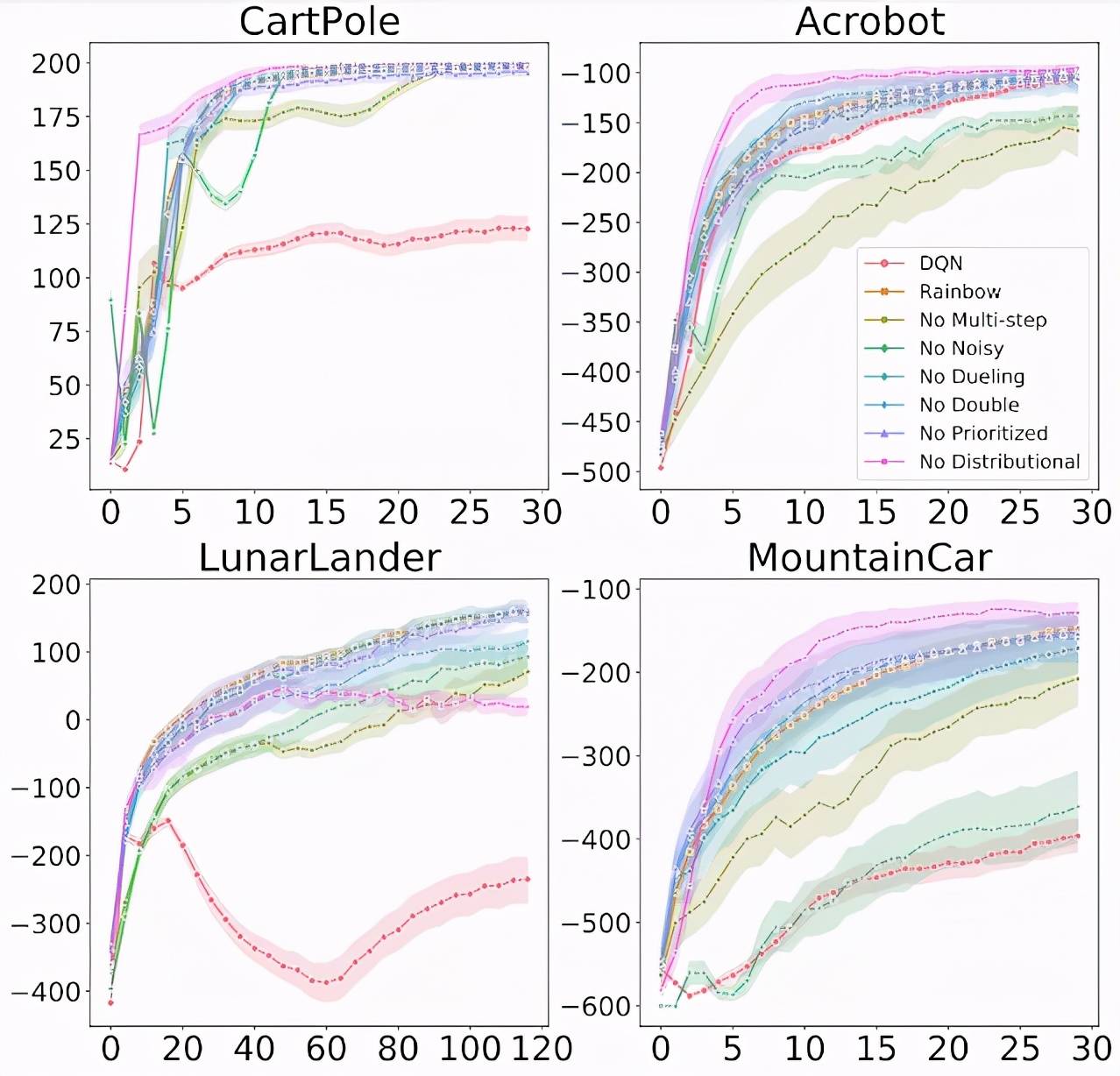
上图显示了在 4 个经典控制环境中 , 从 Rainbow 中移除各种组件时的训练进度 。 x 轴为训练 step , y 轴为性能(越高越好) 。
研究者还在 MinAtar 环境中重新运行了 Rainbow 实验 , MinAtar 环境由一组五个小型化的 Atari 游戏组成 , 实验结果与原 Rainbow 论文类似 。 MinAtar 游戏的训练速度大约是常规 Atari 2600 游戏的 10 倍 , 其中后者的训练速度是在最初的 Rainbow 算法上评估的 。 此外 , 该研究的实验结果还有一些有趣的方面 , 例如游戏动态和给智能体添加基于像素的输入 。 因此 , 该研究提供了一个具有挑战性的中级环境 , 介于经典控制和完整的 Atari 2600 游戏之间 。
综合来看 , 研究者发现现在的结果与原始 Rainbow 论文的结果一致——每个算法组件产生的影响可能因环境而异 。 研究者建议使用单一智能体来平衡不同算法组件之间的权衡 , 该研究的 Rainbow 版本可能与原始版本高度一致 , 这是因为将所有组件组合在一起会产生整体性能更好的智能体 。 然而 , 在不同算法组件之间 , 有一些重要的细节变化值得进行更彻底的探究 。
「优化器 - 损失函数」不同组合实验
DQN 被提出时 , 同时采用了 Huber 损失和 RMSProp 优化器 。 对于研究者而言 , 在构建 DQN 时使用相同的选择是一种常见的做法 , 因为研究者将大部分时间用在了其他算法设计上 。
而该研究重新讨论了 DQN 在低成本、小规模经典控制和 MinAtar 环境中使用的损失函数和优化器 。 研究者使用 Adam 优化器进行了一些初始实验 , 目前 Adam 优化器是最流行的优化器 , 并在实验中结合使用了一个更简单的损失函数 , 即均方误差损失 (MSE) 。 由于在开发新算法时 , 优化器和损失函数的选择往往被忽略 , 而该研究发现在所有的经典控制和 MinAtar 环境中 , 这二者的改变都能让实验结果有显著的改进 。
因此 , 研究者将两个优化器(RMSProp、Adam 优化器)与两个损失函数(Huber、MSE 损失)进行了不同的组合 , 并在整个 ALE 平台(包含 60 款 Atari 2600 游戏)上进行了评估 。 结果发现 Adam+MSE 组合优于 RMSProp+Huber 组合 。
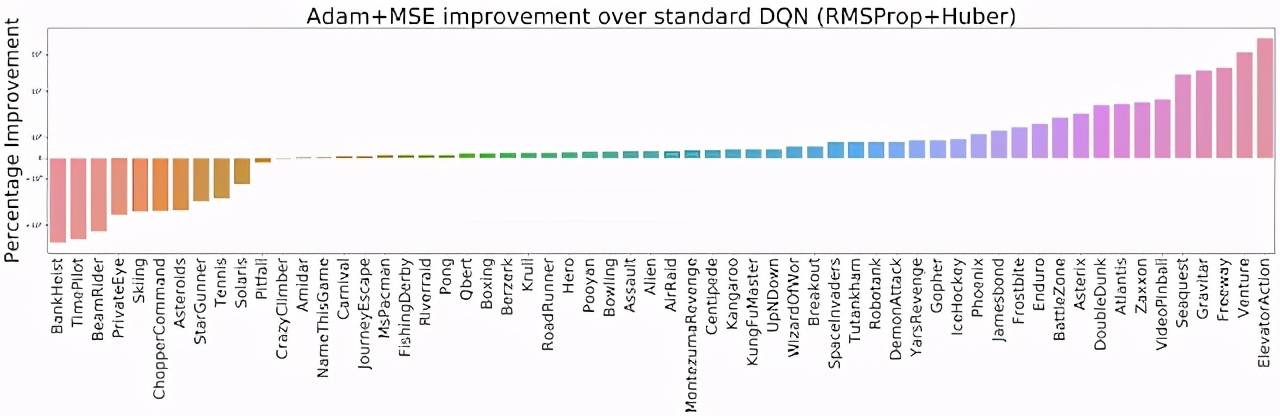
文章图片
在默认 DQN 设置下(RMSProp + Huber) , 评估 Adam+MSE 组合带来的改进(越高越好) 。
此外 , 在比较各种「优化器 - 损失函数」组合的过程中 , 研究者发现当使用 RMSProp 时 , Huber 损失往往比 MSE 表现得更好(实线和橙色虚线之间的间隙可以说明这一点) 。
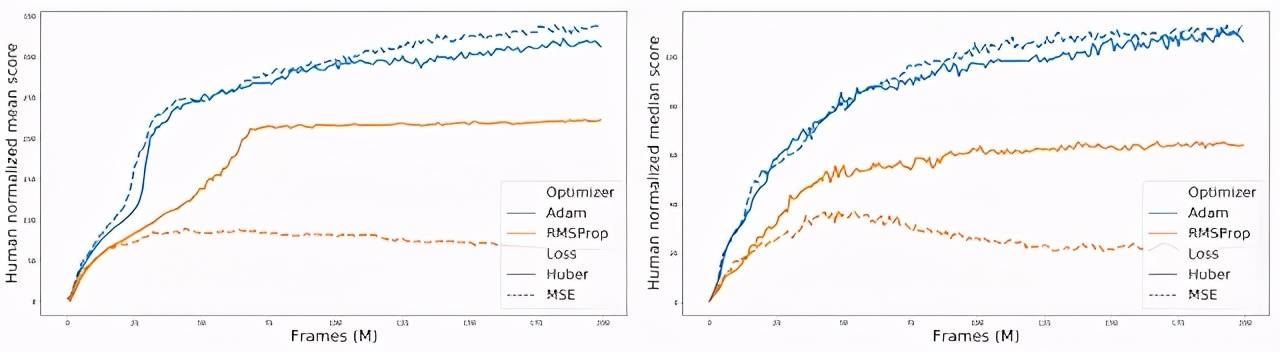
文章图片
对 60 款 Atari 2600 游戏的标准化得分进行汇总 , 比较不同的「优化器 - 损失函数」组合 。
在有限的计算预算下 , 该研究研究者能够在高层次上复现论文《Rainbow: Combining Improvements in Deep Reinforcement Learning》的研究 , 并且发现新的、有趣的现象 。 显然 , 重新审视某事物比首次发现更容易 。 然而 , 研究者开展这项工作的目的是为了论证中小型环境实证研究的相关性和重要性 。 研究者相信 , 这些计算强度较低的环境能够很好地对新算法的性能、行为和复杂性进行更关键和彻底的分析 。 该研究希望 AI 研究人员能够把小规模环境作为一种有价值的工具 , 评审人员也要避免忽视那些专注于小规模环境的实验工作 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。