具体地说 , 该系统使用来自 Megatron-LM 的 tensor-slicing 来扩展节点内的模型 , 并使用来自 DeepSpeed 的 pipeline 并行来跨节点扩展模型 。
例如 , 对于 5300 亿参数的模型 , 每个模型副本(replica)跨越 280 个英伟达 A100 GPU , 具有节点内的 8 路 tensor-slicing 和跨节点的 35 路 pipeline 并行 。 然后再使用 DeepSpeed 的数据并行进一步扩展到数千个 GPU 。
硬件系统
模型训练是在基于英伟达 DGX SuperPOD 的 Selene 超级计算机上以混合精度完成的 , 该超级计算机由 560 个 DGX A100 服务器提供支持 , 这些服务器以完满的胖树配置用 HDR InfiniBand 联网 。 每个 DGX A100 有 8 个英伟达 A100 80GB Tensor Core GPU , 并通过 NVLink 和 NVSwitch 实现相互之间的全连接 。 微软在 Azure NDv4 云超级计算机中使用了类似的架构 。
系统吞吐量
研究者度量了该系统在 Selene 上的 280、350 和 420 DGX A100 服务器上 , 批大小为 1920 的 5300 亿参数模型的端到端吞吐量 。 其迭代时间分别为 60.1、50.2 和 44.4 秒 , 对应于每个 GPU 126、121 和 113 teraFLOP/s 。
数据集和模型配置
研究者使用了 Transformer 解码器架构 , 它是一个从左到右生成的基于 Transformer 的语言模型 , 由 5300 亿个参数组成 。 层数、隐藏维度和注意力头数量分别为 105、20480 和 128 个 。
基于开源数据集集合 The Pile , 研究者构建了训练数据集 。 The Pile 共 835GB , 是 22 个较小数据集的集合 , 涵盖学术资源(例如 , Arxiv、PubMed)、社区(StackExchange、Wikipedia)、代码存储库(Github)等 , 微软和英伟达还引入了 Common Crawl 的大量网页快照 , 包括新闻报道和社交媒体帖子 。
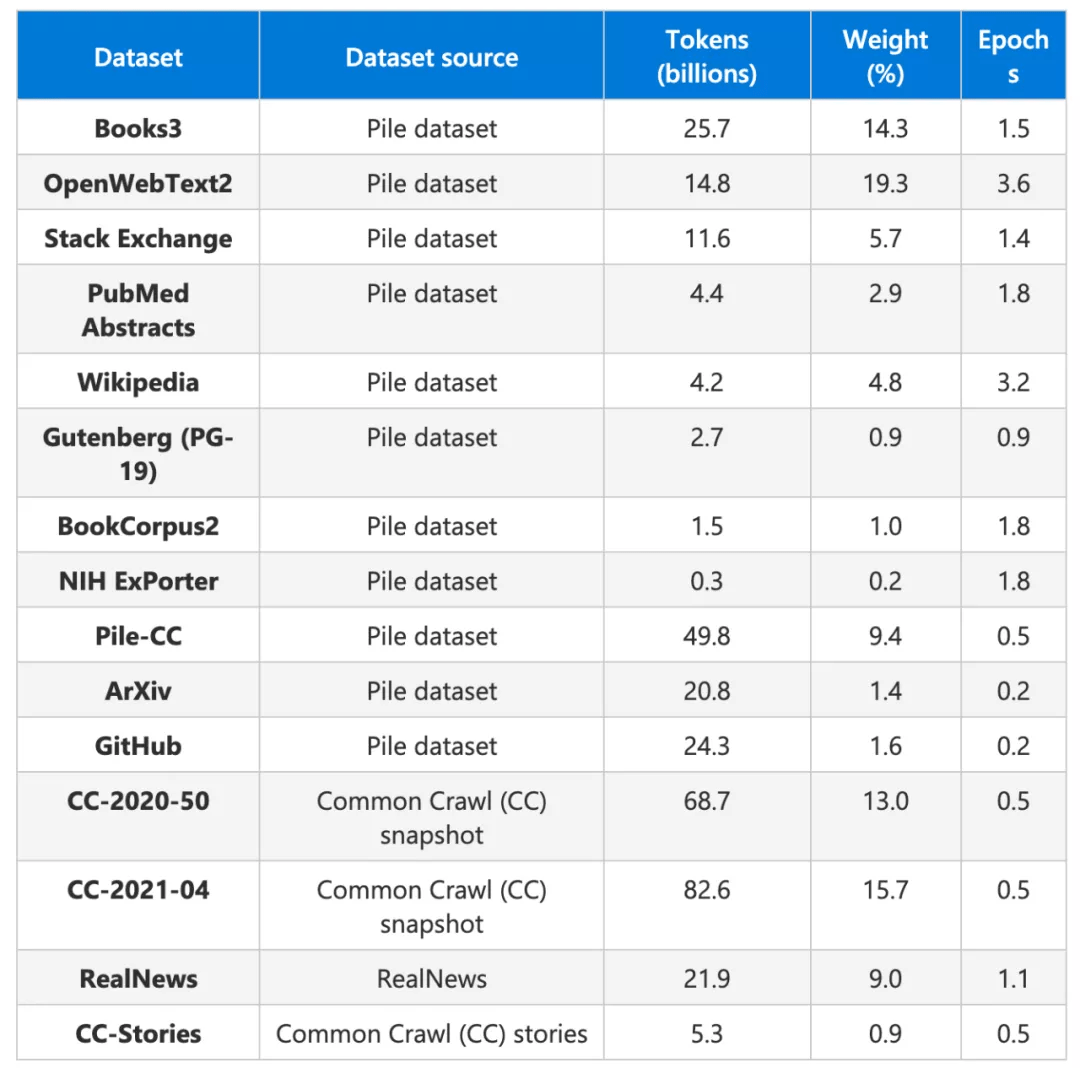
最终的训练集包括 15 个数据集 , 总共有 3390 亿个 token 。 研究者在训练期间根据图 2 中给出的可变采样权重将数据集混合到异构批次中 , 将重点放在更高质量的数据集上 , 在 2700 亿个 token 上训练了模型 。
文章图片
表 1:用于训练 MT-NLG 模型的数据集 。
训练结果
近期语言模型方面的工作表明 , 强大的预训练模型通常可以在不进行微调的情况下 , 在众多 NLP 任务中表现出色 。
为了理解扩大语言模型如何增强其零样本学习或小样本学习能力 , 研究者评估了 MT-NLG, 并证明它在几类 NLP 任务中实现了新的 SOTA 。 为确保评估的全面性 , 研究者选择了跨越五个不同领域的八项任务:
- 在文本预测任务 LAMBADA 中 , 模型预测给定段落的最后一个词;
- 在阅读理解任务 RACE-h 和 BoolQ 中 , 模型根据给定的段落生成问题的答案;
- 在常识推理任务 PiQA、HellaSwag 和 Winogrande 中 , 每个任务都需要一定程度的常识水平 , 超出语言的统计模式才能解决;
- 对于自然语言推理 , ANLI-R2 和 HANS 两个基准 , 针对过去模型的典型失败案例;
- 词义消歧任务 WiC, 从上下文评估多义词的理解 。
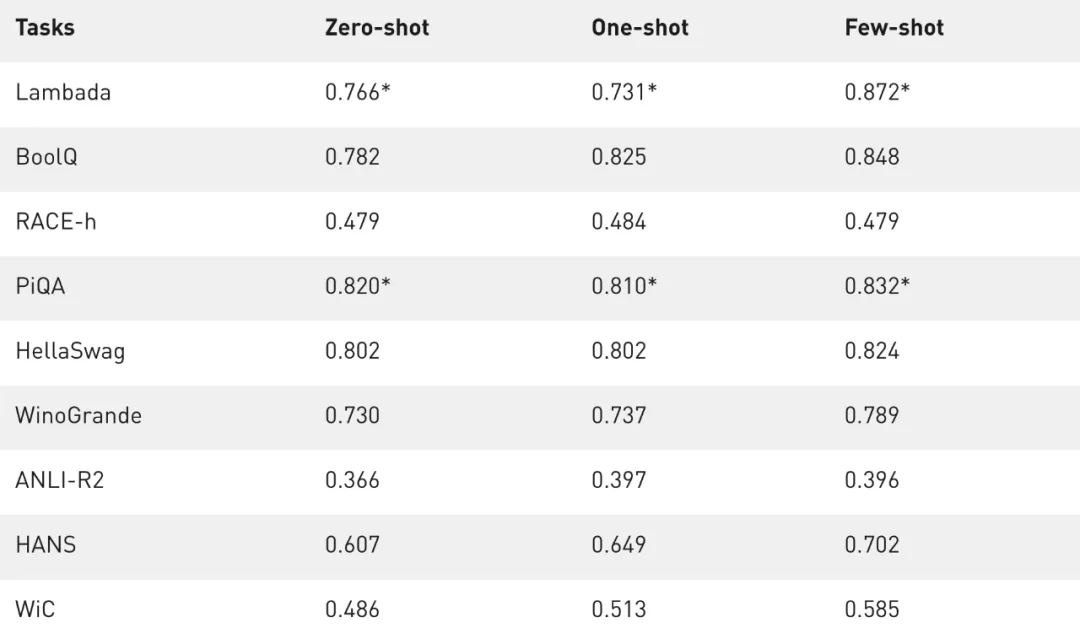
表 2 展示了准确率度量的结果 。 如果测试集是公开可用的 , 研究者会在测试集上进行评估 , 否则即报告开发集上的值 。 最终公开的是 LAMBADA、RACE-h 和 ANLI-R2 上的测试集和开发集上的其他任务 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。