文章图片
表 2:MT-NLG 在 PiQA 开发集和 LAMBADA 测试集的所有设置上都实现了 SOTA(用 * 表示) , 并且在其他类别的类似单体模型中同样表现出色 。
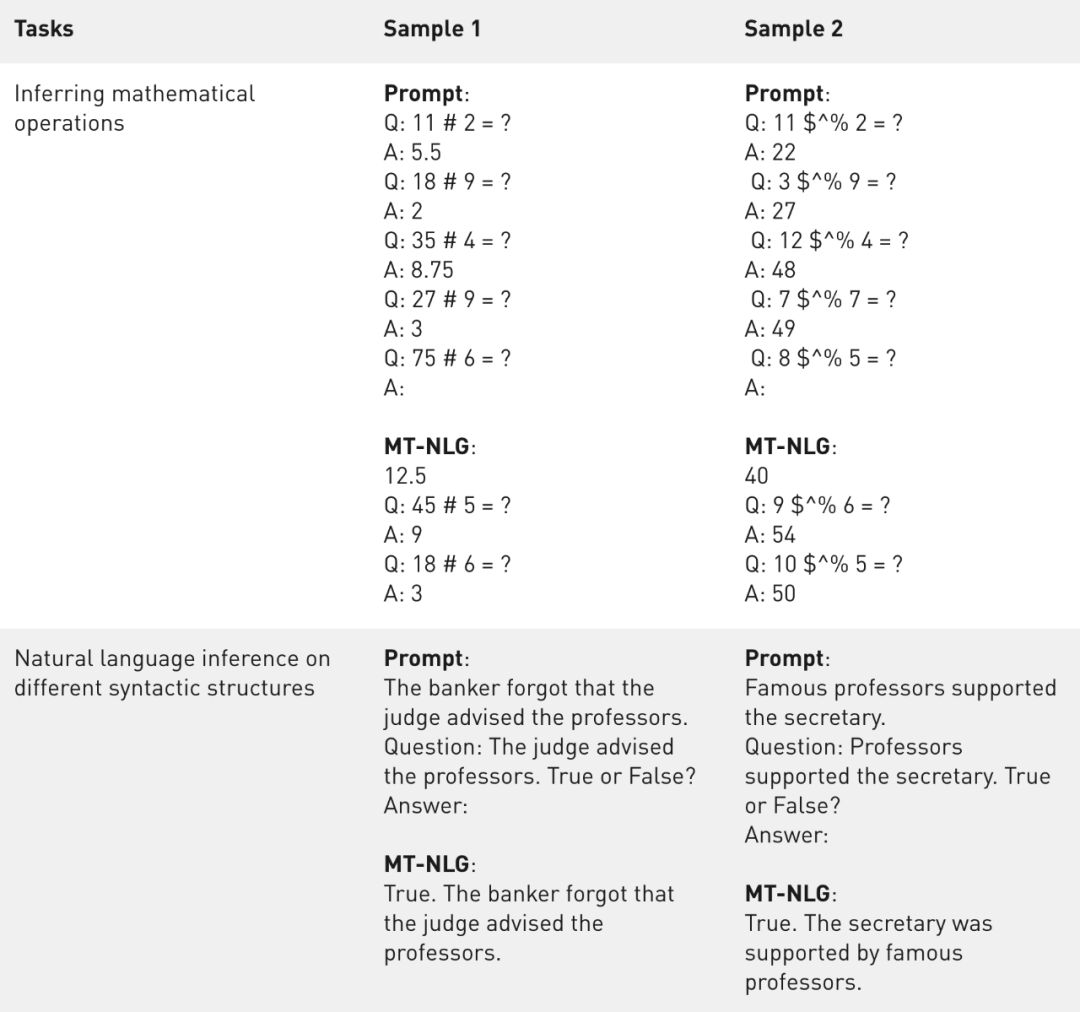
除了基准任务的指标外 , 研究者还对模型输出进行了定性分析 。 可以观察到 , 即使符号被严重混淆(示例 2) , 该模型也可以从上下文中推断出基本的数学运算(示例 1) 。 虽然称不上拥有了算术能力 , 但该模型似乎超越了仅记忆算术的水平 。
文章图片
表 3:MT-NLG 在不同句法结构下的数学运算推理和自然语言推理的样本 。
讨论:问题与应用
虽然大规模语言模型推动了语言生成技术的发展 , 但它们也存在偏见、有害性等问题 。 AI 社区的成员们也一直在积极研究、理解和消除语言这些模型中的问题 。
微软和英伟达表示 , MT-NLG 模型从它所训练的数据中提取了刻板印象和偏见 。 他们正在解决这个问题 , 也鼓励帮助量化模型偏差的后续研究 。
今天 , 人工智能技术的进步正在超越摩尔定律的极限 。 新一代的 GPU 以闪电般的速度互连 , 不断升级算力 。 与此同时 , AI 模型的扩展带来了更好的性能 , 而且似乎前景无限 。
MT-NLG 就是一个例子 , 它展示的是:当像 NVIDIA Selene 或 Microsoft Azure NDv4 这样的超级计算机与 Megatron-LM 和 DeepSpeed 的软件创新一起用来训练大型语言 AI 模型时 , 可能会发生什么?
微软和英伟达表示 , DeepSpeed 和 Megatron-LM 的创新将助力未来更多的 AI 模型开发 , 并使大型 AI 模型的训练成本更低、速度更快 。
尽管如此 , 大模型的成本问题仍然是不可忽视的 。 像 MT-NLP、华为的盘古α、Naver 的 HyperCLOVA、智源研究院的悟道 2.0 等巨模型的搭建成本并不便宜 。 比如说 , OpenAI 的 GPT-3 的训练数据集大小为 45 TB , 足以填满 90 个 500GB 硬盘 。
人工智能训练成本在 2017 年至 2019 年间降低到了原有的百分之一 , 但这仍超过大多数初创公司在计算方面的预算 。 这种不平等牺牲了小企业获得资源的机会 , 反而巩固了巨头原本就具备的优势 。
举一个极端的例子 , 据 CrowdStorage 统计 , 特斯拉自动驾驶团队的一个数据集(1.5 PB 的视频片段)在 Azure 中存储三个月的成本 , 就超过了 67500 美元 。
正如 Huggingface 联合创始人 Julien Chaumond 所说:「比起 5300 亿参数的大模型 , 我更感兴趣的是能让 5.3 亿人使用或研究的模型 。 」

文章图片
参考链接:
https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
【5300亿参数的「威震天-图灵」,微软英伟达合力造出超大语言模型】https://venturebeat.com/2021/10/11/microsoft-and-nvidia-team-up-to-train-one-of-the-worlds-largest-language-models/
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。