目标: 基于HBE(History-Based Executing)的异常SQL识别
有了上述目标以后我们主要通过如下方式进行了SQL黑名单的识别切换
- SQL识别限定在相同appName中(缩小识别范围避免识别错误)
- 得到SQL抽象语法树的后续遍历内容后生成md5值作为该sql的唯一性标识
- 把执行失败超过N次的SQL信息写入黑名单
- 下次执行时根据赋值规则比较两条SQL的结构树特征
- 对于在黑名单中的SQL不进行Spark SQL切换
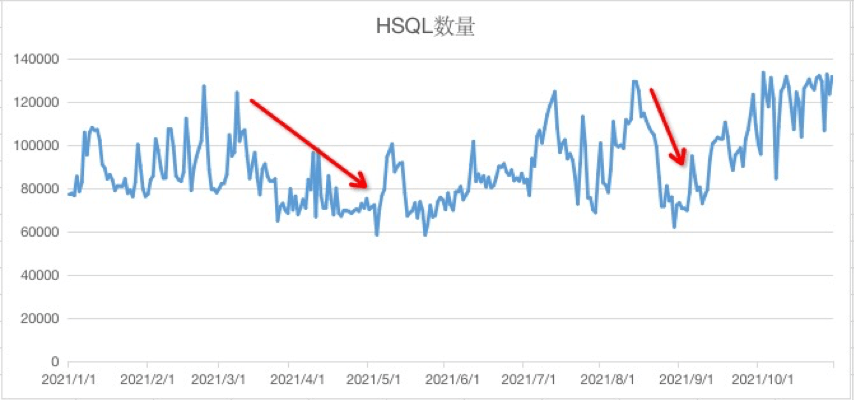
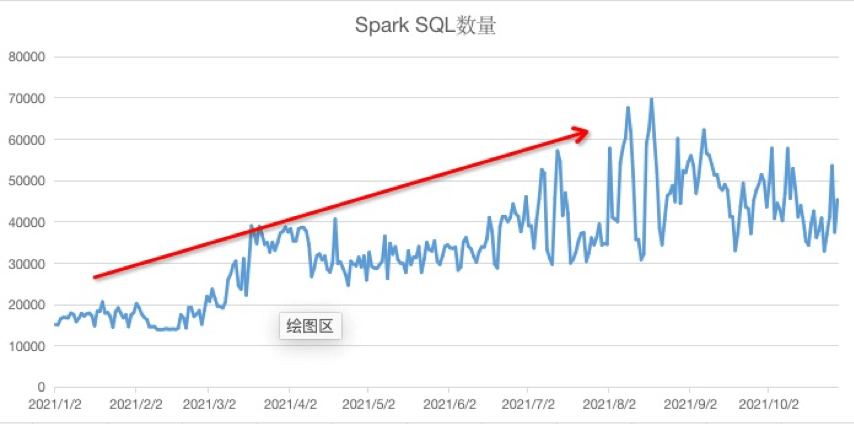
今年经过迁移程序的迁移改造,HSQL最大降幅为50%+(后随今年业务增长有所回升)
【极光笔记丨Spark SQL 在极光的建设实践】
文章图片
文章图片
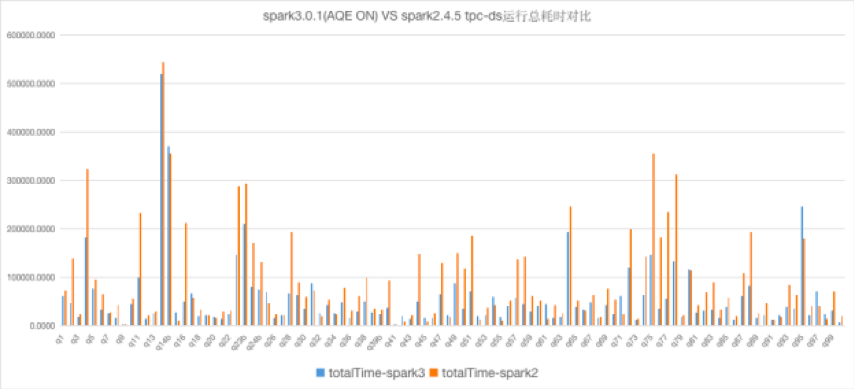
四、Spark3.0的应用 当前极光使用的Spark默认版本已经从2.X版本升级到了3.X版本,Spark3.X的AQE特性也辅助我们更好的使用Spark
文章图片
实践配置优化:
#spark3.0.0参数
#动态合并shuffle partitions
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.coalescePartitions.minPartitionNum 1
spark.sql.adaptive.coalescePartitions.initialPartitionNum 500
spark.sql.adaptive.advisoryPartitionSizeInBytes 128MB
#动态优化数据倾斜,通过实际的数据特性考虑,skewedPartitionFactor我们设置成了1
spark.sql.adaptive.skewJoin.enabled true
spark.sql.adaptive.skewJoin.skewedPartitionFactor 1
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 512MB
五、后续规划 目前针对线上运行的Spark任务,我们正在开发一套Spark全链路监控平台,作为我们大数据运维平台的一部分,该平台会承担对线上Spark任务运行状态的采集监控工作,我们希望可以通过该平台及时定位发现资源使用浪费、写入大量小文件、存在slow task等问题的Spark任务,并以此进行有针对性的优化,让数据平台可以更高效的运行 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。