
文章图片
极光高级工程师——蔡祖光
前言 Spark在2018开始在极光大数据平台部署使用,历经多个版本的迭代,逐步成为离线计算的核心引擎 。 当前在极光大数据平台每天运行的Spark任务有20000+,执行的Spark SQL平均每天42000条,本文主要介绍极光数据平台在使用Spark SQL的过程中总结的部分实践经验,包括以下方面内容:
- Spark Extension的应用实践
- Spark Bucket Table的改造优化
- 从Hive迁移到Spark SQL的实践方案
1.1 血缘关系解析
在极光我们有自建的元数据管理平台,相关元数据由各数据组件进行信息收集,其中对Spark SQL的血缘关系解析和收集就是通过自定义的Spark Extension实现的 。
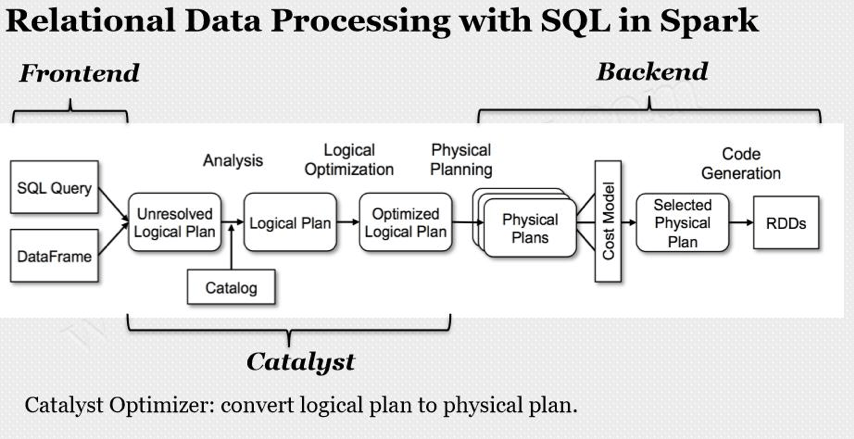
Spark Catalyst的SQL处理分成parser , analyzer , optimizer以及planner等多个步骤 , 其中analyzer , optimizer等步骤内部也分为多个阶段,为了获取最有效的血缘关系信息,我们选择最终的planner阶段作为切入点,为此我们专门实现了一个planner strategy进行Spark SQL物理执行计划的解析,并提取出读写表等元数据信息并存储到元数据管理平台
文章图片
1.2 权限校验
在数据安全方面,极光选择用Ranger作为权限管理等组件,但在实际使用的过程中我们发现目前社区版本的Ranger主要提供的还是HDFS、HBase、Hive、Yarn的相关接入插件,在Spark方面需要自己去实现相关功能,对于以上问题我们同样选择用Spark Extension去帮助我们进行权限方面的二次开发,在实现的过程中我们借助了Ranger Hive-Plugin的实现原理,对Spark SQL访问Hive进行了权限校验功能的实现 。
1.3 参数控制
随着数据平台使用Spark SQL的业务同学越来越多,我们发现每个业务同学对于Spark的熟悉程度都有所不同,对Spark配置参数的理解也有好有坏,为了保障集群整体运行的稳定性,我们对业务同学提交的Spark任务的进行了拦截处理,提取任务设置的配置参数,对其中配置不合理的参数进行屏蔽,并给出风险提示,有效的引导业务同学进行合理的线上操作 。
二、Spark Bucket Table的改造优化 在Spark的实践过程中,我们也积极关注业内其它公司优秀方案,在2020年我们参考字节跳动对于Spark Bucket Table的优化思路,在此基础上我们对极光使用的Spark进行了二次改造,完成如下优化项:
- Spark Bucket Table和Hive Bucket Table的互相兼容
- Spark支持Bucket Num是整数倍的Bucket Join
- Spark支持Join字段和Bucket字段是包含关系的Bucket Join
通过对数据平台过往SQL执行记录的分析,我们发现用户ID和设备ID的关联查询是十分高频的一项操作,在此基础上,我们通过之前SQL血缘关系解析收集到的元数据信息,对每张表进行Join、Aggregate操作的高频字段进行了分析整理,统计出最为合适的Bucket Cloumn,并在这些元数据的支撑下辅助我们进行Bucket Table的推广改造 。
三、Hive迁移Spark 随着公司业务的高速发展,在数据平台上提交的SQL任务持续不断增长,对任务的执行时间和计算资源的消耗都提出了新的挑战,出于上述原因,我们提出了Hive任务迁移到Spark SQL的工作目标,由此我们总结出了如下问题需求:
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。