强化学习(以及深度 Q 学习)是什么?
与监督学习相反,强化学习不需要手动标注训练数据 。而是与环境互动,观察互动的结果 。多次重复这个过程,获得积极和消极经验作为训练数据 。因此,我们通过实验而不是模仿来学习 。
假设我们的环境处于一个特定的状态 s,当采取动作 a 时,它会变为状态 s\' 。对于这个特定的动作,你在环境中观察到的即时奖励是 r 。这个动作之后的任何一组动作都有自己的即时奖励,直到你因为积极或消极经验而停止互动 。这些叫做未来奖励 。因此,对于当前状态 s,我们将尝试从所有可能的动作中估计哪一个动作将带来最大的即时+未来奖励,表示为 Q(s,a),即 Q 函数 。由此得到 Q(s,a) = r + γ * Q(s\', a\'),表示在 s 状态下采取动作 a 的预期最终奖励 。由于预测未来具有不确定性,因此此处引入折扣因子 γ,我们更倾向于相信现在而不是未来 。

文章插图
深度 Q 学习是一种特殊的强化学习技术,Q 函数是通过深度神经网络学习的 。给定环境的状态作为这个网络的图像输入,它试图预测所有可能动作的预期最终奖励,像回归问题一样 。选择具有最大预测 Q 值的动作作为我们在环境中要采取的动作 。该技术因此得名「深度 Q 学习」 。
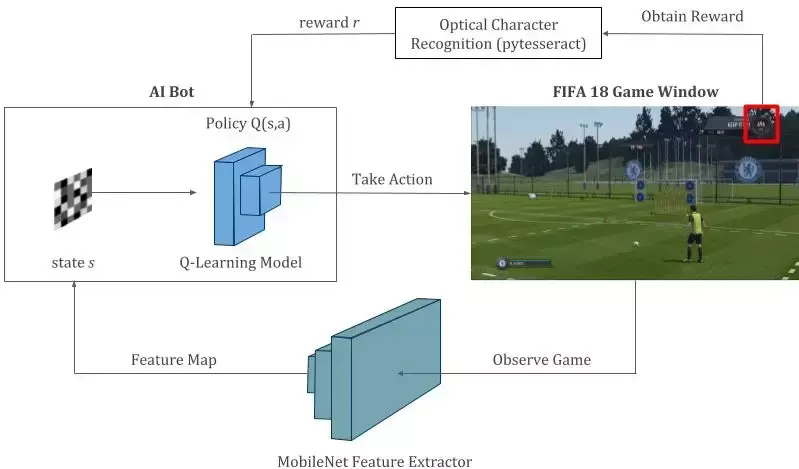
将 FIFA 任意球定位为 Q 学习问题
- 状态:通过 MobileNet CNN 处理的游戏截图,给出了 128 维的扁平特征图 。
- 动作:四种可能的动作,分别是 shoot_low、shoot_high、move_left、move_right.
- 奖励:如果按下射门,比赛成绩增加 200 分以上,我们就进了一个球,r=+1 。如果球没进,比分保持不变,r=-1 。最后,对于与向左或向右移动相关的动作,r=0 。
- 策略:两层密集网络,以特征图为输入,预测所有 4 个动作的最终奖励 。
文章插图
智能体与游戏环境交互的强化学习过程 。Q 学习模型是这一过程的核心,负责预测智能体可能采取的所有动作的未来奖励 。该模型在整个过程中不断得到训练和更新 。
注意:如果我们在 FIFA 的开球模式中有一个和练习模式中一样的性能表(performance meter),那么我们可能就可以将整个游戏作为 Q 学习问题,而不仅仅局限于任意球 。或者我们需要访问我们没有的游戏内部代码 。不管怎样,我们应该充分利用现有的资源 。
代码实现
我们将使用 Tensorflow (Keras) 等深度学习工具在 Python 中完成实现过程 。
【fifa21所有球队 fifa18】GitHub 地址:
https://github.com/ChintanTrivedi/DeepGamingAI_FIFARL
- 二月你好早安心语 二月简短早安心语
- 所有口袋精灵 手机版口袋精灵
- 淘宝提前收款是所有订单吗 淘宝提前收款是什么
- 武炼苍穹 《弑天剑仙》
- 赞美女人气质高雅漂亮的词句
- 在什么情况下公民可能丧失所有权
- 如何分割夫妻双方所有的财产
- 所有家族名称 家族成员系列名字
- 房子共同所有离婚怎么样分割 离婚时
- 宝马驻车关闭所有灯光 宝马驻车灯怎么关
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。