文章图片
表1 不同方法的定量比较结果
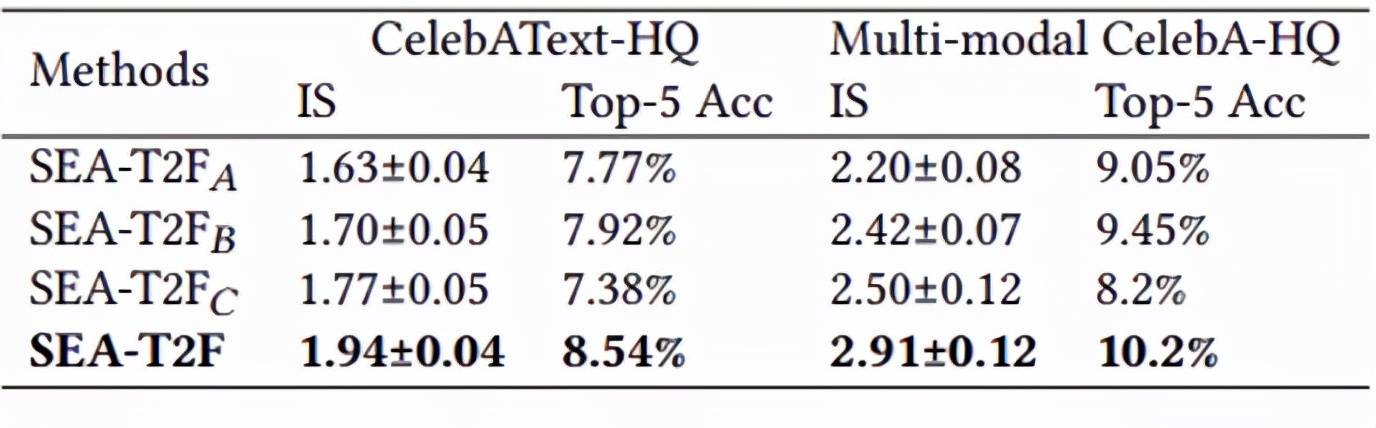
文章图片
表2 消融实验结果:前三行分别表示网络去除SFIM , AMC , 和属性分类损失 。
参考文献:
1. Osaid Rehman Nasir, Shailesh Kumar Jha, Manraj Singh Grover, Yi Yu, Ajit Kumar, and Rajiv Ratn Shah. 2019. Text2FaceGAN: face generation from fine grained textual descriptions. In IEEE International Conference on Multimedia Big Data (BigMM). 58–67.
2. Xiang Chen, Lingbo Qing, Xiaohai He, Xiaodong Luo, and Yining Xu. 2019. FTGAN: A fully-trained generative adversarial networks for text to face generation. arXiv preprint arXiv:1904.05729 (2019).
3. David Stap, Maurits Bleeker, Sarah Ibrahimi, and Maartje ter Hoeve. 2020. Conditional image generation and manipulation for user-specified content. arXiv preprint arXiv:2005.04909 (2020).
4. Weihao Xia, Yujiu Yang, Jing-Hao Xue, and Baoyuan Wu. 2021. TediGAN: Textguided diverse image generation and manipulation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2256–2265.
5. Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. 2018. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1316–1324.
6. Bowen Li, Xiaojuan Qi, Thomas Lukasiewicz, and Philip Torr. 2019. Controllable text-to-image generation. In Advances in Neural Information Processing Systems (NeuIPS). 2065–2075.
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。