另一方面 , 随着一代又一代新加速器的出现 , ML 中的异构环境变得越来越普遍 。 提供对(通过高带宽 interconnect 连接的)同构加速器的大「岛」的独占访问是昂贵的 , 并且通常会造成浪费 , 因为单个用户程序必须努力保持所有加速器持续忙碌 。 这种限制进一步推动研究人员走向「多程序多数据」(MPMD)计算 。 MPMD 通过将整个计算的子部分映射到一组更容易获得的小加速器岛上来实现更大的灵活性 。 为了提高利用率 , 一些 ML 硬件资源管理研究人员以细粒度的方式在工作负载之间复用硬件 , 实现工作负载弹性 , 并提高容错能力 。
最后 , 研究人员开始标准化一套基础模型(foundation model) , 这些模型是在大数据上大规模训练的 , 可以适应多种下游任务 。 通过在许多任务之间复用资源 , 并在它们之间有效地共享状态 , 这种模型的训练和推理提供了提高集群利用率的机会 。 例如 , 几个研究人员可能同时微调用于不同任务的一个基础模型 , 使用相同的加速器来保持固定的基础模型层 。 在共享的子模型上进行的训练或推理可以受益于一些技术 , 这些技术允许来自不同任务的示例被组合在一个 vectorized batch 中 , 以获得更高的加速器利用率 。
本文提出的 PATHWAYS 在功能和性能上可以媲美 SOTA ML 系统 , 同时提供了支持未来 ML 工作负载所需的能力 。 它使用了一个 client-server 架构 , 该架构使得 PATHWAYS 的运行时能够代表许多 client 在系统管理计算岛上执行程序 。
PATHWAYS 是第一个旨在透明、高效地执行跨多个 TPU pods 的程序的系统 。 通过采用新的数据流执行模型 , 它可以扩展到数千个加速器 。 PATHWAYS 的编程模型使得表达非 SPMD 计算变得很容易 , 并支持集中的资源管理和虚拟化 , 以提高加速器的利用率 。
PATHWAYS 系统架构
PATHWAYS 构建在先前的系统的基础上 , 包括用于表征和执行 TPU 计算的 XLA (TensorFlow, 2019)、用于表征和执行分布式 CPU 计算的 TensorFlow 图和执行器 (Abadi et al., 2016) , 以及包括 JAX (Bradbury et al., 2016) 在内的 Python 编程框架 (Bradbury et al., 2018) 和 TensorFlow API 。 利用这些构建块 , PATHWAYS 在兼顾协调性的同时 , 仅用最少的代码更改就能运行现有的 ML 模型 。
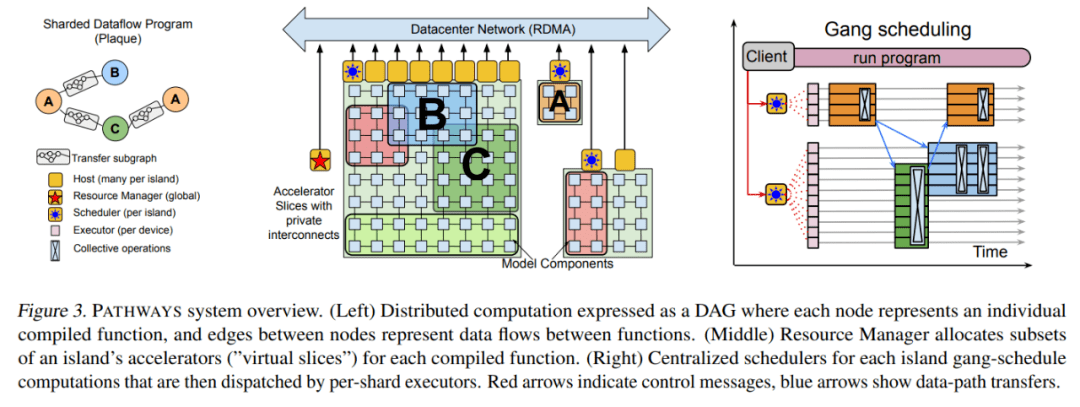
文章图片
资源管理器
PATHWAYS 的后端由一组加速器组成 , 这些加速器组合成紧密耦合的 island , 这些 island 又通过 DCN 相互连接 , 如上图 3 所示 。 PATHWAYS 有一个「资源管理器」 , 负责集中管理所有 island 上的设备 。 client 可能会要求 island 的「虚拟 slice」具有适合其通信模式的特定 2D 或 3D 网格形状 。 每个虚拟 slice 都包含「虚拟设备」 , 允许 client 表达计算在网格上的布局方式 。 资源管理器为满足所需互连拓扑、内存容量等的虚拟设备动态分配物理设备 。
最初的资源管理器使用一个简单的启发式方法来实现 , 尝试通过在所有可用设备上传播计算来静态平衡负载 , 并在虚拟设备和物理设备之间保持一对一的映射 。 如果未来的工作负载需要 , 则可以采用更加复杂的分配算法 , 例如考虑所有 client 计算的资源需求和系统的当前状态 , 以近似计算物理设备的最佳分配 。
PATHWAYS 允许动态添加和移除后端计算资源 , 由资源管理器跟踪可用设备 。 由单控制器设计启用的虚拟设备和物理设备之间的间接层将允许未来支持透明的挂起 / 恢复和迁移等功能 , 其中 client 的虚拟设备可以临时回收资源或重新分配而无需用户程序的协助 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。