如前所述 , 在一组共享加速器上支持 SPMD 计算的一个要求是支持高效的 gang-scheduling 。
PATHWAYS 运行时包括每个 island 的集中式调度器 , 它对 island 上所有计算进行一致性排序 。 当 PATHWAYS 将一个程序加入队列以执行时 , PLAQUE 数据流程序负责以下操作:
- 在每个加速器上将本地编译函数执行加入队列 , 并将缓冲 future 作为输入;
- 将网络发送(network sends)加入到远程加速器的队列 , 以获得函数执行输出的缓冲 future;
- 与调度器通信 , 以确定在 island 上运行的所有程序中函数执行的一致顺序 。
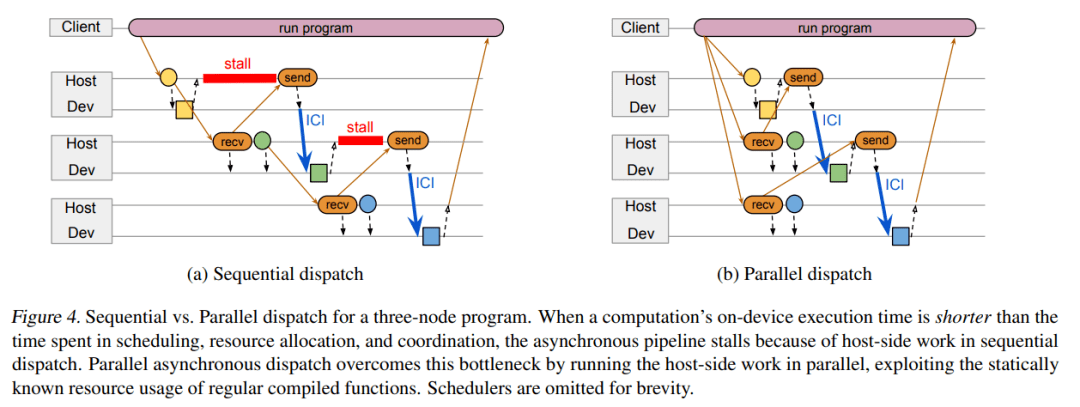
并行异步调度
当在加速器上运行计算时 , 系统可以利用异步 API 将计算与协调重叠 。 如下图 4a 中的三节点图所示 , 正方形分别对应三个节点 A、B 和 C , 它们在连接到主机 A、B 和 C 的加速器上运行 。 所有节点计算都是常规编译函数 。 主机 A 将节点 A 加入队列 , 接收 A 输出的 future 并将它传输给主机 B 。 主机 B 分类节点 B 的输入 , 将该输入缓冲地址传输给节点 A , 并执行大部分准备工作以启动节点 B 的功能 。 当节点 A 完成时 , 它的输出直接通过加速器互联发送至节点 B 的输入缓冲 , 然后主机 B 启动节点 B 。 一个节点完成和另一个节点启动之间的延迟时间要比数据传输时间更长 。
当 predecessor 节点的计算时间超过主机之间调度、资源分类和协同所用时间时 , 上述设计运行良好 。 但如果计算时间太短 , 异步 pipeline 就会停止 , 主机端的工作成为执行整个计算序列过程中的关键瓶颈 。 考虑到编译的函数都是常规的 , 后续节点的输入形状实际上可以在 predecessor 计算加入队列之前进行计算 。
因此 , 谷歌引入了一种全新的并行异步调度设计方案 , 具体如下图 4 b 所示 。 该方案利用常规编译函数的静态已知资源来并行运行计算节点的主机端工作 , 而不是在 predecessor 已经加入队列之后对节点工作进行序列化处理 。 考虑到常规函数下只能并行地调度工作 , PATHWAYS 将并行调度作为一种优化手段 , 并在节点资源需求在 predecessor 计算完成时才知道的情况下回退到传统模型 。
当计算的子图可以进行静态调度时 , 该程序会向调度器发送描述整个子图的单条消息 , 该调度器能够对子图中所有活动分片的执行进行背靠背排序 。 设计单条消息旨在最小化网络流量 , 但不需要调度器将所有子图的分片作为一个批次来加入队列:计算仍可能与其他并发执行程序提交的计算交错 。
文章图片
三节点程序的顺序调度(a)与并行调度(b)比较 。
实验结果
谷歌展示了 PATHWAYS 在训练真实机器学习模型(它们可以被表示为 SPMD 程序)中的性能 。 首先与使用编码器 - 解码器架构运行 Transformer 模型的 JAX 多控制器进行比较 。
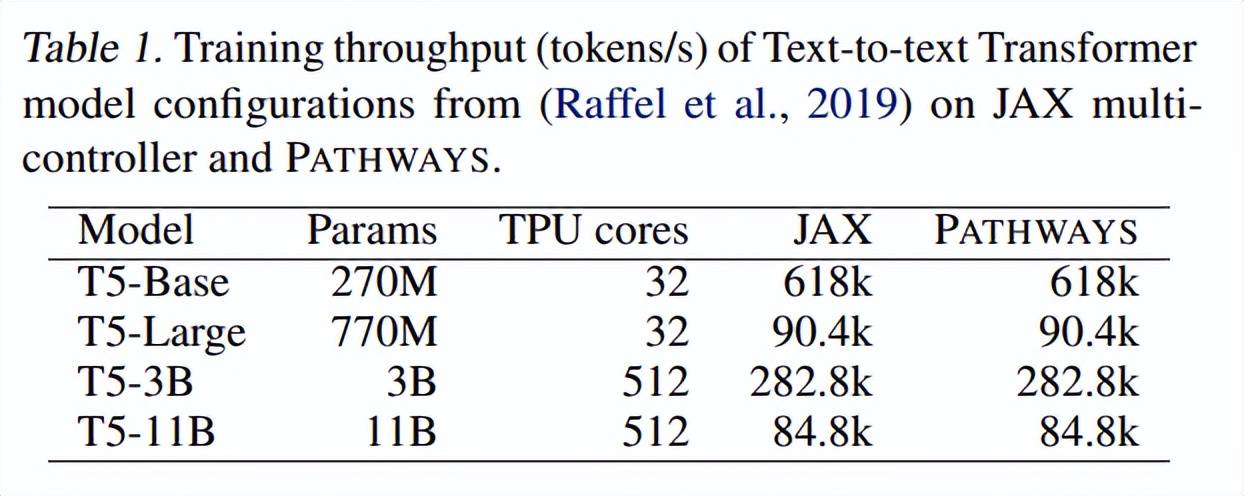
下表 1 展示了在不同数量的加速器上训练时 , 不同大小的文本到文本 Transformer 模型的训练吞吐量(tokens / 秒) 。 正如所预期的一样 , 由于模型代码相同 , 在 JAX 和 PATHWAYS 上训练的模型在步数相同的情况下实现了相同的困惑度 。
文章图片
接着 , 谷歌比较了当仅用解码器架构训练 Transformer 语言模型时 , PATHWAYS 在不同配置上的性能 。 如表 2 所示 , PATHWAYS 的训练吞吐量与每个 pipeline 阶段的 TPU 核心数量成比例增加 , 这与其他系统保持一致 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。