【谷歌下一代AI架构、Jeff Dean宣传大半年的Pathways终于有论文了】client
当用户想要运行一个被跟踪的程序时 , 可以调用 PATHWAYS client 库 , 它首先将虚拟设备分配给之前没有运行过的任何计算 , 并用资源管理器注册计算 , 触发 server 在后台编译计算 。
然后 , client 为程序构建与设备位置无关的 PATHWAYS 中间表征 (IR) , 表示为自定义 MLIR (Lattner et al., 2021) dialect 。 IR 通过一系列标准编译器 pass 逐渐降低级别 , 最终输出包含物理设备位置的低级表征 。 这种低级程序考虑了物理设备之间的网络连接 , 并包含将输出从源计算分片传输到其目标分片(shard)位置的操作 , 包括需要数据交换时的分散和收集操作 。 在虚拟设备位置不变的通常情况下重复运行低级程序是有效的 , 如果资源管理器改变了虚拟设备和物理设备之间的映射关系 , 可以 re-low 程序 。
较旧的单控制器系统中的 client 可能很快成为性能瓶颈 , 因为它负责协调数千个单独的计算 , 还要协调分布在数千个加速器中的计算分片相应的数据缓冲区 。 PATHWAYS client 使用分片缓冲区抽象来表征可能分布在多个设备上的逻辑缓冲区 。 这种抽象通过以逻辑缓冲区而不是单个分片的粒度分摊 bookkeeping 任务(包括参考计数(reference counting))的成本来帮助 client 扩展 。
协调实现
PATHWAYS 依赖 PLAQUE 完成所有使用 DCN 的跨主机协调 。 PLAQUE 是一种现有的(闭源)生产分片数据流系统 , 谷歌将它用于许多面向客户的服务 , 这些服务需要高扇出或高扇入通信 , 并且可扩展性和延迟都很重要 。 低级 PATHWAYS IR 直接被转换为 PLAQUE 程序 , 并表征为数据流图 。 PATHWAYS 对其协调 substrate 有严格的要求 , 而 PLAQUE 满足所有要求 。
首先 , 用于描述 PATHWAYS IR 的表征必须包含每个分片计算的单个节点 , 以确保能够紧凑表征跨多个分片的计算 , 即带有 N 个计算分片的 2 个计算 A 和 B 的链式执行 , 无论 N 是多少 , 每个计算分片在数据流表征中都有 4 个节点:Arg → Compute (A) → Compute (B) → Result 。 在 PLAQUE 运行时实现中 , 每个节点都会生成带有目标分片标记的输出数据元组 , 因此在执行数据并行执行时 , N 个数据元组将在每对相邻的 IR 节点之间流动 。
协调运行时还必须支持沿分片边缘的稀疏数据交换 , 其中消息可以在动态选择的分片子集之间发送 , 使用标准的进度跟踪机制(Akidau et al., 2013; Murray et al., 2013)来检测何时已收到分片的所有消息 。 高效的稀疏通信能够避免 DCN 成为加速器上依赖于数据的控制流瓶颈 , 这是 PATHWAYS 启用的关键功能之一 。
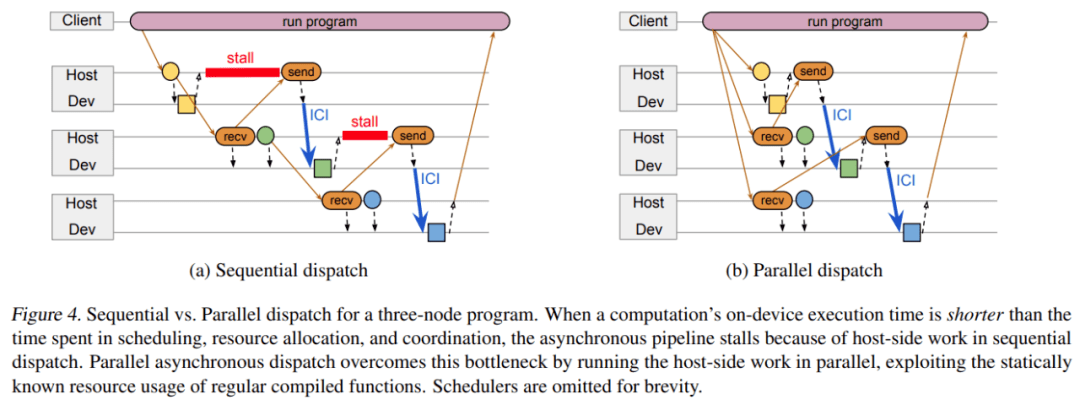
如下图 4 所示 , 协调 substrate 用于发送传输调度消息和数据 handle 的关键路径中的 DCN 消息 , 因此它必须以低延迟发送关键消息 , 并在需要高吞吐量时将消息批量发送到同一个 host 。
文章图片
使用可扩展的通用数据流引擎来处理 DCN 通信也很方便 , 因为这意味着 PATHWAYS 还可以将其用于后台管理任务 , 例如分发配置信息、监控程序、清理程序、在出现故障时提示错误等 。
谷歌认为 , 使用 Ray (Moritz et al., 2018) 等其他分布式框架而不是 PLAQUE 来重新实现完整的 PATHWAYS 设计以实现低级协调框架是可行的 。 在这种实现中 , PATHWAYS 执行器和调度器将被长期运行的 Ray Actor 所取代 , 这些 Ray Actor 将在底层 Ray 集群调度之上实现 PATHWAYS 调度 , 并且执行器可以使用 PyTorch 进行 GPU 计算和集合 。
Gang-scheduled 动态调度
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。