超过 5 × 5 矩阵和类似大小的矩形矩阵 , 训练模型精度与向量乘法相同(在 1% 容差下超过 99%) , 但需要更深的解码器(4 到 6 层) 。

文章插图
特征值
我们把注意力转向由迭代算法解决的非线性问题 。
作者在编码器或解码器中训练 4 层或 6 层的模型 , 用以预测对称矩阵的特征值 。
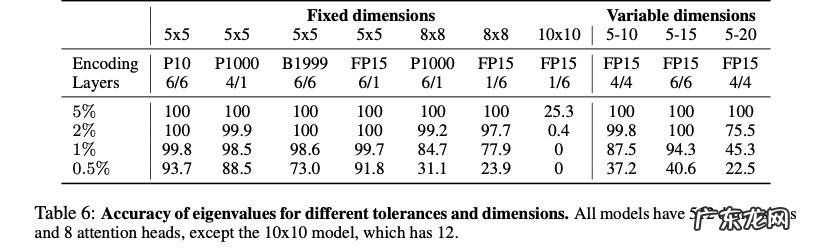
对于 5 × 5 随机矩阵的样本 , 在 5% 的容差下达到 100% 的准确率 , 在所有四种编码下达到 98.5% 的 1% 。 对于 8 × 8 矩阵 , 在 5% 和 1% 的容差下实现了 100% 和 85% 的准确率 。
但也遇到了瓶颈 , 对于大规模问题 , 模型难以学习:在 10 × 10 矩阵上 , 3.6 亿个示例可达 25% 的准确率和 5% 的容差 。 相比之下 , 对于 5 × 5 矩阵 , 模型在大约 4000 万个样本中训练到最高准确率 , 对于 8 × 8 矩阵 , 模型在大约 6000 万个样本中训练到最高准确率 。
这个限制通过在可变大小的数据集上训练模型能够克服 。 在维度为 5-10、5-15 和 5-20 的矩阵样本上 , 模型在 5% 的容差下达到 100% 的准确率 , 在 1% 容差下达到 88%、94% 和 45% 。 使用 5-15 模型 , 10 × 10 矩阵的特征值可以在 2% 的容差下以 100% 的准确率进行预测 , 在 1% 容差时为 73% 。 结果如下图所示 。
文章插图
特征向量
除了特征值 , 作者还预测了特征向量的正交矩阵 。
在 5 × 5 矩阵上 , 使用 P10 和 P1000 编码的模型在 5% 容差的情况下 , 实现了 97.0% 和 94.0% 的准确率 。 FP15 型号的性能较弱 , 准确率为 51.6% , 但非对称型号 , 带有 6 层 FP15 编码器和 1 层 P1000 解码器 , 在 5% 容差下的准确率为 93.5% , 在 1% 容差下的准确率为 67.5% 。 P1000 模型可以预测 6 × 6 矩阵的特征向量 , 预测准确率为 81.5% 。

文章插图
奇异值分解
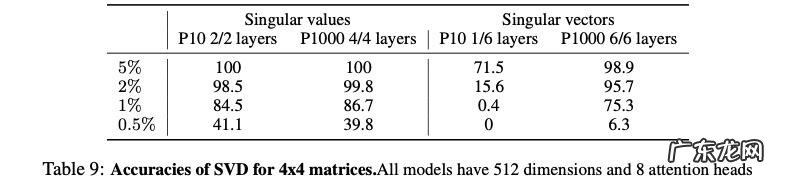
虽然这项任务与特征分解有关 , 但事实证明它的学习难度更大:使用 P10 或 P1000 编码的多达 6 层 Transformer 可以预测 4 × 4 矩阵的奇异值分解 。 单奇异值(容差为 5% 和 1%)的准确率较高 , 分别为 100% 和 86.7% , 完全分解的准确率分别为 98.9% 和 75.3% 。
文章插图
此外 , 域外泛化和再训练中 , 作者为了训练模型 , 生成独立同分布 ( iid ) 系数的随机 n × n 矩阵 , 从 [ A, A ] 上的均匀分布中采样 。
Transformer 如果想要解决线性代数问题 , 了解在 Wigner 矩阵上训练模型在不同特征值分布的矩阵上执行方法十分重要 。
研究人员创建了 10,000 个矩阵的测试集 , 其分布与训练集不同 。 然后 , 生成不同特征值分布的矩阵的测试集:正特征值(特征值替换为其绝对值的 Wigner 矩阵) , 以及根据均匀、高斯或拉普拉斯定律的特征值分布 , 标准偏差为 和 。
为了提高分布外的准确性 , 作者在具有不同特征值分布的数据集上训练新模型 , 并在之前创建的测试集上评估它们 。

文章插图
最终得到一个重要结果:常被视为随机矩阵默认模型的 Wigner 矩阵可能不是训练 Transformer 的最佳选择 。 非分布泛化需要特别注意训练数据的生成 。
- 女生晚上喝普洱茶好吗?这个茶起减肥作用吗
- 花王泡沫染发剂好用吗 花王泡沫染发剂如何
- 卷发棒要预热多久 卷发棒的使用频率
- 施华蔻直发乳怎么用 施华蔻直发乳正确使用方法
- 卷发棒怎么用不伤头发 经常用卷发棒的危害
- 老板一年不发工资怎么办?用劳动法积极维护个人权益,建议收藏
- 快手光合计划一周能领多少钱?有什么用?
- 快手变现都用什么类型?有什么类型的视频?
- 顺产后多久使用收腹带?多久有效果?
- 假发可以喷啫喱水吗 假发可以用发蜡吗
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。