阿里机器智能

文章插图
小叽导读:在淘宝这个平台上,消费者每天都在浏览着琳琅满目的图片,图片是消费者与商品交互的第一媒介 。图片的质量会极大影响消费者的消费体验和转化效果,高质量的图片会让消费者怦然心动,流连忘返,而低质量的“辣眼睛”图片会让消费者望而却步 。在淘宝首页猜你喜欢(以下简称首猜)场景下,由于图片数量太多,让人工来审核所有图片是不现实的 。作为阿里技术人,我们的使命就是使用技术手段过滤掉低质量的图片,将高质量的图片和素材呈现给消费者 。
一、摘要
恶心图片,顾名思义,就是让人感到恶心,不适的图片 。其大致可以被分为跟动物有关的,跟人有关的,以及物体这三种类型 。要从数量巨大的商品池中精确地将恶心图片过滤出来,面临着以下几个技术难点:
(1)初始样本很少且难收集,面临模型冷启动的问题;
(2)线上真实数据场景下,正负样本比例差距过大,面临严重的类别不平衡问题;
(3)恶心样本多种多样,如昆虫,爬行动物,人的各个身体部位等等,样本的特征分布非常分散 。
针对第一个问题,我们通过本团队的小样本平台从淘宝内容池中召回恶心图片扩充样本量,并通过半监督算法利用淘宝的无标签数据进行训练 。针对第二个问题,我们在训练中通过online hard example mining +级联的方法,并且通过active learning和噪声样本识别算法加快模型迭代 。针对第三个问题,我们在模型中引入了attention机制,让模型focus在恶心的局部区域 。本文的二、三、四节分别论述了这三个解决方案 。
模型于19年10月初在首猜上线,在集团的各个业务场景下累计召回了几万张恶心图片 。最新版的模型的精确率为95%,召回率为94% 。
二、冷启动方案
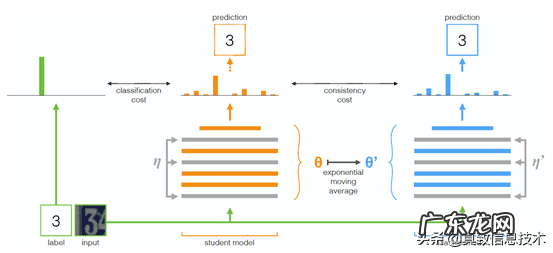
由于初始样本量比较少,面临冷启动的问题 。我们从首猜负反馈数据里拿到了几百张恶心图片,并通过本团队的小样本召回平台,用图像检索的方法从淘宝内容池中召回了几百张恶心图片,组成了最开始的训练样本 。为了防止过拟合,我们采用了轻量级的网络mobilenet v2 。另外,我们通过半监督算法利用淘宝的无标签数据进行训练,提高模型的泛化能力 。具体思想为:一个网络的输出可以被认为是

文章插图
,其中W是网络参数,X是输入图片 。一个好的模型应该足够鲁棒,无论是W的扰动(本文称为参数扰动)还是X的扰动(本文称为输入扰动),输出都应该保持不变 。训练流程如下所示:
文章插图
对于有标签数据,对student网络的输出构造交叉熵损失函数,对于所有数据(无标签+有标签),对student网络和teacher网络(两个网络结构一致)的输出构造MSE损失函数 。每次迭代的时候使用梯度下降法更新student网络参数并使得teacher网络的参数成为student网络参数的滑动指数平均 。(具体可参考论文《Mean teachers are better
rolemodels:Weight-averaged consistency targets improve semi-supervised deeplearning results》)如下式所示:

文章插图
在参数扰动上,我们使用的是上述公式中的滑动指数平均 。在输入扰动上,我们对student网络和teacher网络的输入做了不同的数据增强 。我们使用了随机翻转,randomresizedcrop,random erasing等方法,在后来召回来的badcase中,发现有一部分召回来的负样本是化了妆的嘴唇、眼部、脸部等,这些区域和某些恶心图正样本比较相似 。因此尝试了random_distort的方法,经过处理之后,类似的badcase基本消除 。
- 淘宝相当于美国的什么 淘宝美国
- 直通车恶意点击怎么办 淘宝恶意点击直通车软件
- 淘小铺现在还可以赚钱吗 淘小铺怎样赚钱
- 免费注册淘宝账号 淘宝网注册淘宝账号
- 淘宝店铺营销方案 淘宝产品营销方案
- 海外代购 淘宝海外代购耐克是真的吗
- 淘宝店标制作教程 淘宝店标制作方法
- 淘宝新品福利购物券 淘宝购物券怎么买
- 淘宝秒杀什么意思
- 淘宝商品会自动上架吗 淘宝自动上架什么意思
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。