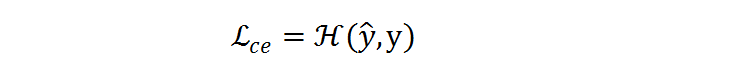
文章图片
梯度被反向传播到分类网络和分辨率预测器以同时优化 。
如果只使用交叉熵损失函数 , 分辨率预测器将会收敛到一个次优点 , 并倾向于选择最大的分辨率 , 因为最大的分辨率往往对应着更低的分类损失 。 为了减少计算量 , 研究者提出了一个 FLOPs constraint regularization 去指导分类预测器的学习:
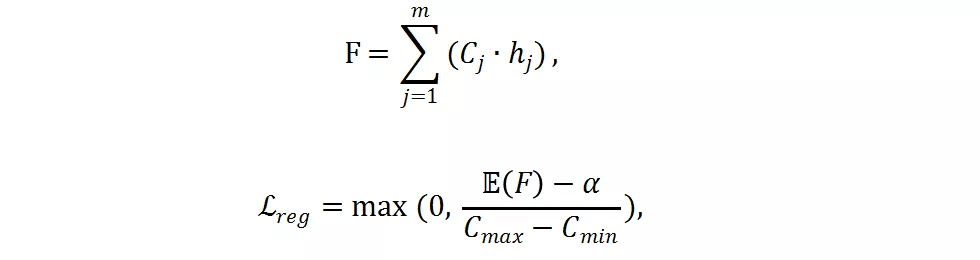
文章图片
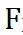
文章图片
是实际 FLOPs , C_j 是预先计算好的第 j 个分辨率的 FLOPs ,
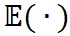
文章图片
是在样本层面的期望值 ,
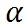
文章图片
是目标 FLOPs 。 经过这个正则 , 如果平均 FLOPs 值过大 , 将会有一个惩罚 , 促使提出的分辨率预测器高效且准确 。 最终 , 整个损失函数是两者加权和:
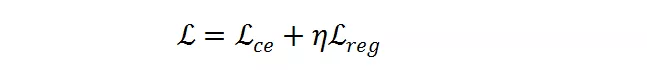
文章图片
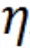
文章图片
是超参数以用于平衡
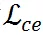
文章图片
和

文章图片
的幅度 。
Gumbel Softmax 可以使得离散的 decision 在反向传播中可微 。 对于前述概率值 P_r = [p_r1, p_r2, , p_rm] , 离散的候选分辨率选择可以由此得到:
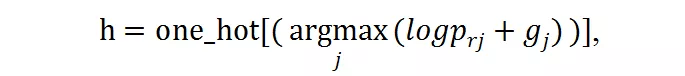
文章图片
g_j 是 gumbel noise , 由下式得到:
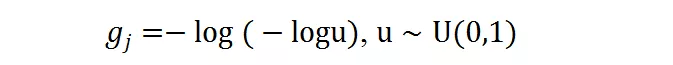
文章图片
在训练过程中 , 独热操作的求导可以由 gumbel softmax 近似 , 其中

文章图片
是温度系数:
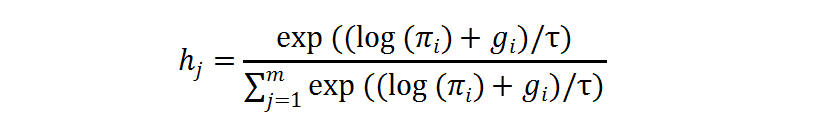
文章图片
实验
研究者在 ImageNet-1K 和 ImageNet-100 数据集上训练和验证 DRNet 模型 , 其中 ImageNet-100 是 ImageNet-1K 的子集 。
ImageNet-100 实验
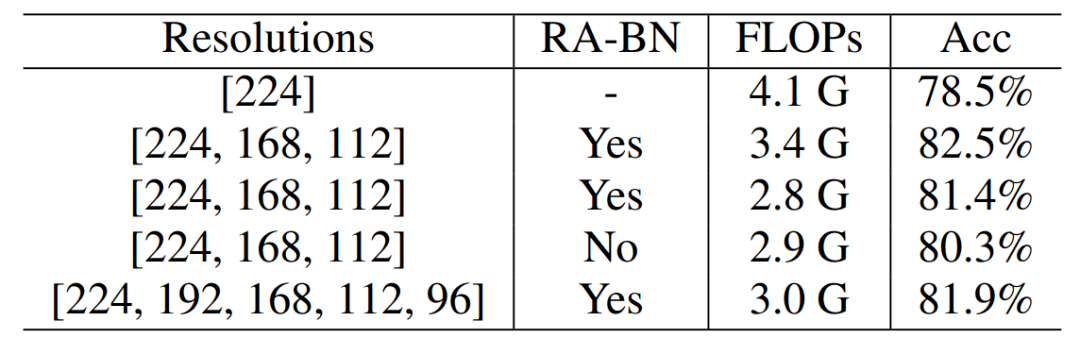
从下表 1 可以看出 , 在 ImageNet-100 数据集上 , DRNet 相比于 ResNet-50 , 减少了 17% 的 FLOPs , 同时获得了 4.0% 的准确率提升 。 当调整超参数和时 , 可以减少 32% 的 FLOPs 并提升 1.8% 准确率 。 另外 , 采用分辨率感知的 BN 获得了性能提升而 FLOPs 相似 。
文章图片
表 1 :ResNet-50 骨干网络在 ImageNet-100 上的结果 。
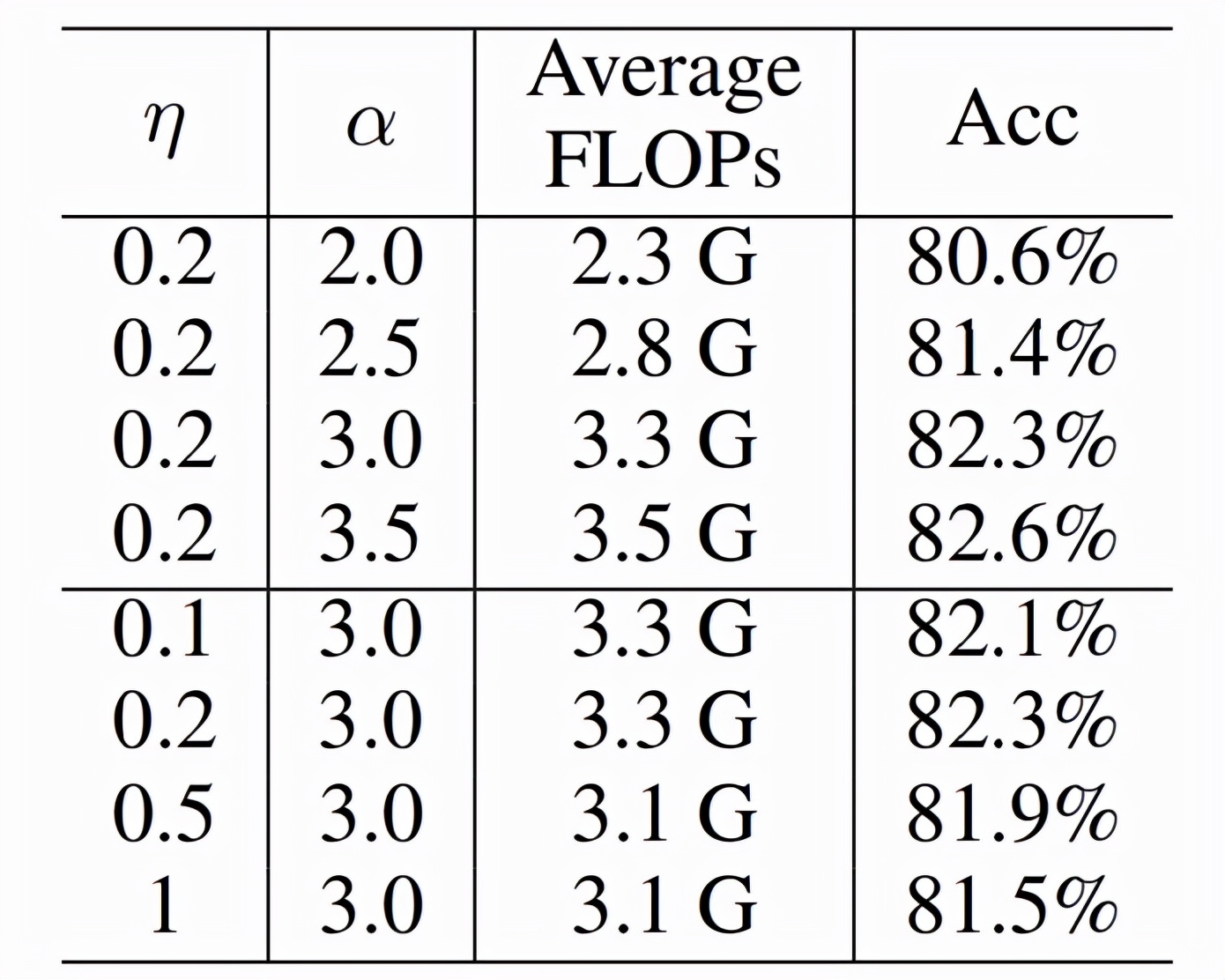
下表 2 中 , 研究者进一步减少 , 可以获得 44% 的 FLOPs 减少而准确率还是增加 。
文章图片
表 2 :FLOPs Loss 的影响 。
ImageNet-1K 实验
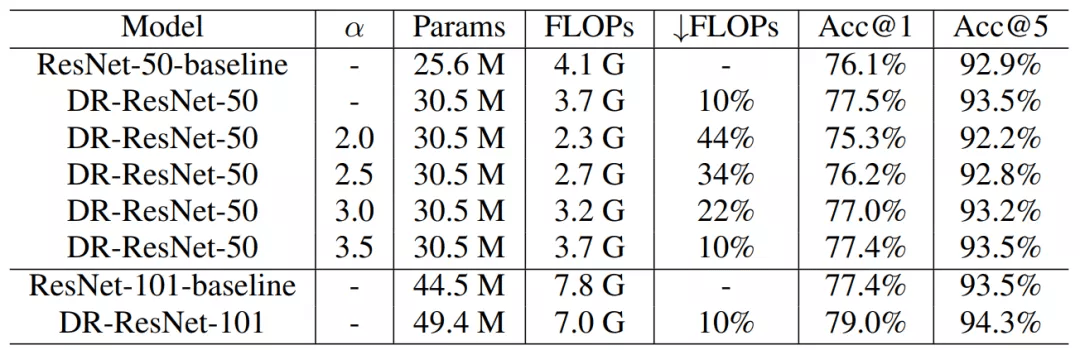
研究者在 ImageNet-1K 上进行大规模实验 , 发现 DR-ResNet-50 减少了 10% 的 FLOPs , 性能提升 1.4% , 如下表 3 所示 。
文章图片
表 3 :ResNet-50 和 ResNet-101 在 ImageNet-1K 上的结果 。
与其他方法的结果比较见下表 4 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。