虽然从 CPU 转向 GPU 架构是朝着正确方向迈出的一大步 , 但这还不够 。 GPU 仍然是传统架构 , 采用与 CPU 相同的计算模型 。 CPU 受其架构限制 , 在科学应用等领域逐渐被 GPU 取代 。 因此 , 通过联合设计专门针对 AI 的计算模型和硬件 , 才有希望在 AI 应用市场占有一席之地 。
文章图片
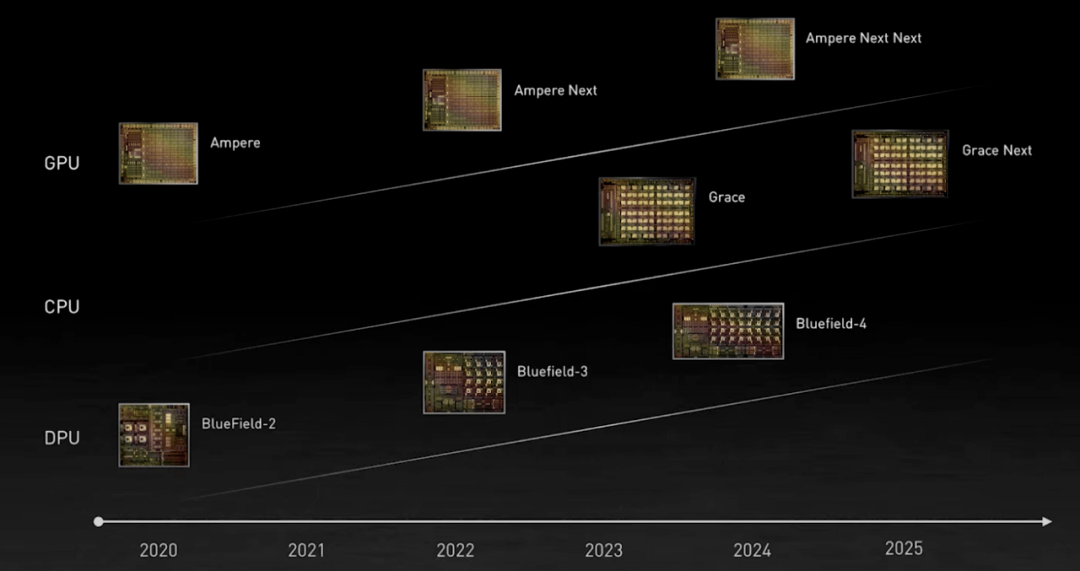
英伟达的 GPU、CPU 和 DPU 路线图 。 图源:英伟达
英伟达主要从两个角度发展 AI:(i) 引入 Tensor Core;(ii) 通过收购公司 。 比如以数十亿美元收购 Mellanox, 以及即将对 ARM 的收购 。
ARM-NVIDIA 首次合作了一款名为「Grace」的数据中心 CPU , 以美国海军少将、计算机编程先驱 Grace Hopper 的名字命名 。 作为一款高度专用型处理器 , Grace 主要面向大型数据密集型 HPC 和 AI 应用 。 新一代自然语言处理模型的训练会有超过一万亿的参数 。 基于 Grace 的系统与 NVIDIA GPU 紧密结合 , 性能比目前最先进的 NVIDIA DGX 系统(在 x86 CPU 上运行)高出 10 倍 。
Grace 获得 NVIDIA HPC 软件开发套件以及全套 CUDA 和 CUDA-X 库的支持 , 可以对 2000 多个 GPU 应用程序加速 。
Cerebras
Cerebras 成立于 2016 年 。 随着 AI 模型变得越来越复杂 , 训练时需要使用更多的内存、通信和计算能力 。 因此 , Cerebras 设计了一个晶圆级引擎 (WSE) , 它是一个比萨盒大小的芯片 。

文章图片
Andrew Feldman 。 图源:IEEE spectrum
典型的处理芯片是在一块称为晶圆的硅片上制造的 。 作为制造过程的一部分 , 晶圆被分解成称为芯片的小块 , 这就是我们所说的处理器芯片 。 一个典型的晶圆可容纳数百甚至数千个这样的芯片 , 每个芯片的尺寸通常在 10 平方毫米到 830 平方毫米左右 。 NVIDIA 的 A100 GPU 被认为是最大的芯片 , 尺寸 826 平方毫米 , 可以封装 542 亿个晶体管 , 为大约 7000 个处理核心提供动力 。
文章图片
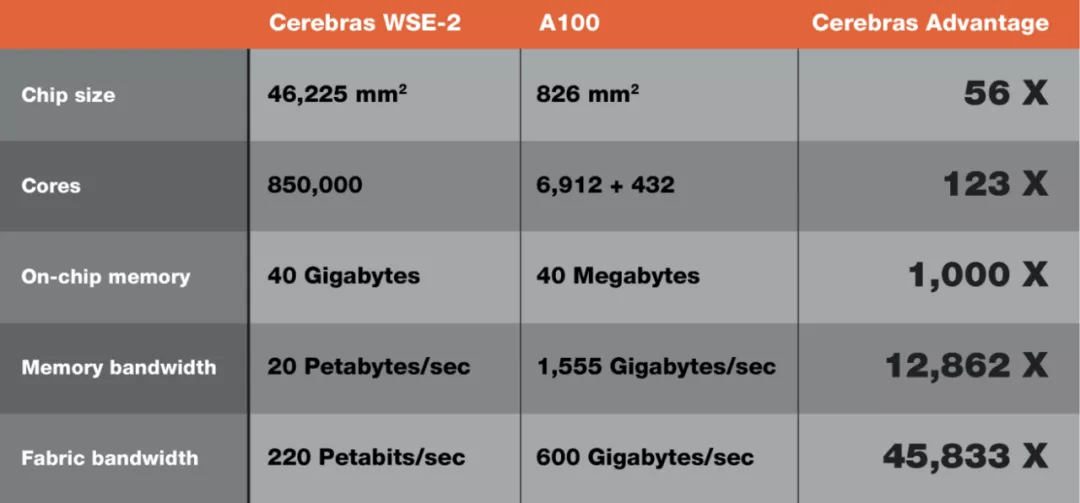
Cerebras WSE-2 与 NVIDIA A100 规格比较 。 图注:BusinessWire
Cerebras 不仅在单个大芯片上提供超级计算机功能 , 而且通过与学术机构和美国国家实验室的合作 , 他们还提供了软件堆栈和编译器工具链 。 其软件框架基于 LAIR(Linear-Algebra Intermediate Representation )和 c++ 扩展库 , 初级程序员可以使用它来编写内核(类似于 NVIDIA 的 CUDA) , 还可用于无缝降低来自 PyTorch 或 TensorFlow 等框架的高级 Python 代码 。
总而言之 , Cerebras 的非传统方法吸引了许多业内人士 。 但是更大的芯片意味着内核和处理器因缺陷而导致失败的可能性更高 , 那么如何控制制造缺陷、如何冷却近百万个核心、如何同步它们、如何对它们进行编程等等都需要逐个解决 , 但有一点是肯定的 , Cerebras 引起了很多人的注意 。
GraphCore
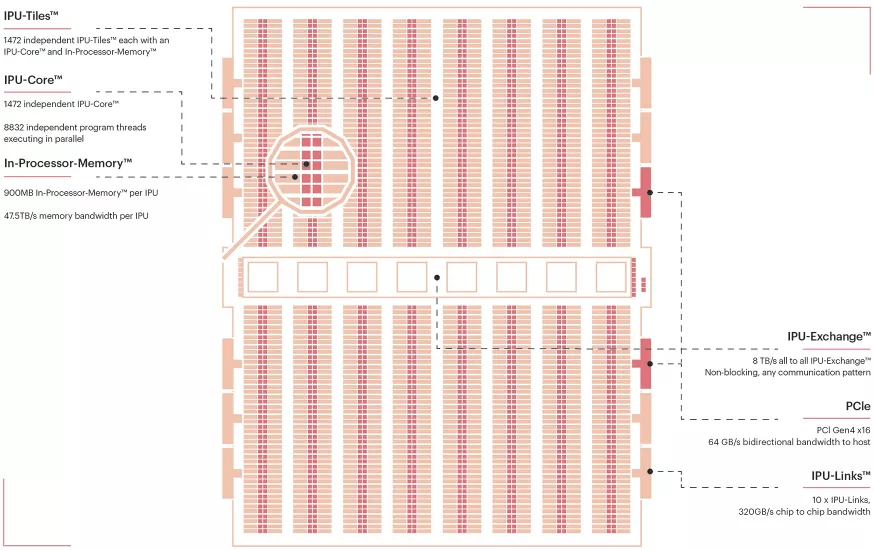
GraphCore 是首批推出商业 AI 加速器的初创公司之一 , 这种加速器被称为 IPU(Intelligent Processing Unit) 。 他们已经与微软、戴尔以及其他商业和学术机构展开多项合作 。
目前 , GraphCore 已经开发了第二代 IPU , 其解决方案基于一个名为 Poplar 的内部软件堆栈 。 Poplar 可以将基于 Pytorch、Tensorflow 或 ONNX 的模型转换为命令式、可以兼容 C++ 的代码 , 支持公司提倡的顶点编程(vertex programming) 。 与 NVIDIA 的 CUDA 一样 , Poplar 还支持低级 C++ 编程以实现更好的潜在性能 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。