选自Medium
作者:Adi Fuchs
机器之心编译
在上一篇文章中 , 前苹果工程师、普林斯顿大学博士 Adi Fuchs 聚焦 AI 加速器的秘密基石:指令集架构 ISA、可重构处理器等 。 在这篇文章中 , 我们将跟着作者的思路回顾一下相关 AI 硬件公司 , 看看都有哪些公司在这一领域发力 。这是本系列博客的第四篇 , 主要介绍了 AI 加速器相关公司 。 全球科技行业最热门的领域之一是 AI 硬件 ,本文回顾了 AI 硬件行业现状 , 并概述相关公司在寻找解决 AI 硬件加速问题的最佳方法时所做的不同赌注 。
对于许多 AI 硬件公司来说 , 最近几年似乎是 AI 硬件发展的黄金时代;过去三年英伟达股价暴涨约 + 500% , 超越英特尔成为全球市值最高的芯片公司 。 其他创业公司似乎同样火爆 , 在过去几年中 , 他们已花费数十亿美元资助 AI 硬件初创公司 , 以挑战英伟达的 AI 领导地位 。
【详解AI加速器(四):GPU、DPU、IPU、TPU…AI加速方案无限种可能】
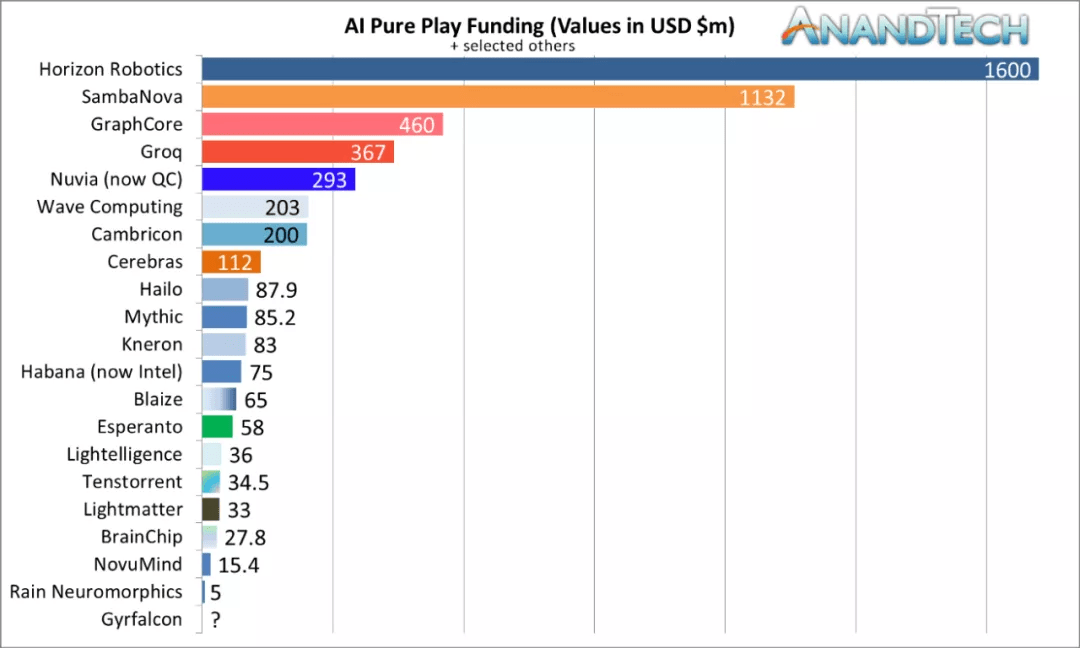
文章图片
AI 硬件初创公司 - 截至 2021 年 4 月的总融资 。 图源:AnandTech
此外 , 还有一些有趣的收购故事 。 2016 年 , 英特尔以 3.5 亿美元收购了 Nervana , 2019 年底又收购了另一家名为 Habana 的人工智能初创公司 , 该公司取代了 Nervana 提供的解决方案 。 非常有意思的是 , 英特尔为收购 Habana 支付了 20 亿美元的巨款 , 比收购 Nervana 多好几倍 。
AI 芯片领域 , 或者更准确地说 , AI 加速器领域(到目前为止 , 它已经不仅仅是芯片)包含了无数的解决方案和方法 , 所以让我们回顾这些方法的主要原则 。
AI 加速器不同实现方法
英伟达:GPU + CUDA
如果你在耕地 , 你更愿意使用哪个?两只壮牛还是 1024 只鸡?(西摩?克雷)英伟达成立于 1993 年 , 是最早研究加速计算的大公司之一 。 英伟达一直是 GPU 行业的先驱 , 后来为游戏机、工作站和笔记本电脑等提供各种 GPU 产品线 , 已然成为世界领导者 。 正如在之前的文章中所讨论的 , GPU 使用数千个简单的内核 。 相比来说 , CPU 使用较少的内核 。
最初 GPU 主要用于图形 , 但在 2000 年代中后期左右 , 它们被广泛用于分子动力学、天气预报和物理模拟等科学应用 。 新的应用程序以及 CUDA 和 OpenCL 等软件框架的引入 , 为将新领域移植到 GPU 铺平了道路 , 因此 GPU 逐渐成为通用 GPU (General-Purpose GPU) , 简称 GPGPU 。
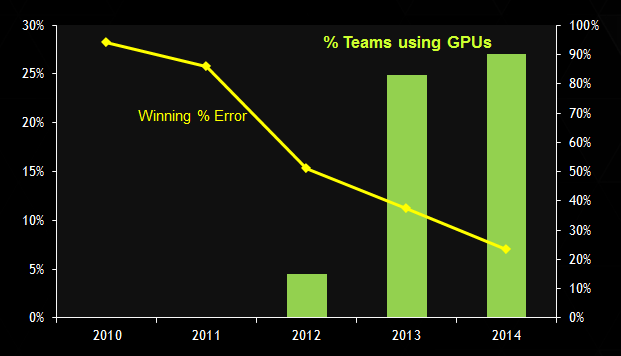
文章图片
ImageNet 挑战赛:使用 GPU 的获胜误差和百分比 。 图源:英伟达
从历史上看 , 人们可能会说英伟达是幸运的 , 因为当 CUDA 流行和成熟时 , 现代 AI 就开始了 。 或者有人可能会争辩说 , 正是 GPU 和 CUDA 的成熟和普及使研究人员能够方便高效地开发 AI 应用程序 。 无论哪种方式 , 历史都是由赢家书写的 —— 事实上 , 最有影响力的 AI 研究 , 如 AlexNet、ResNet 和 Transformer 都是在 GPU 上实现和评估的 , 而当 AI 寒武纪爆发时 , 英伟达处于领先地位 。
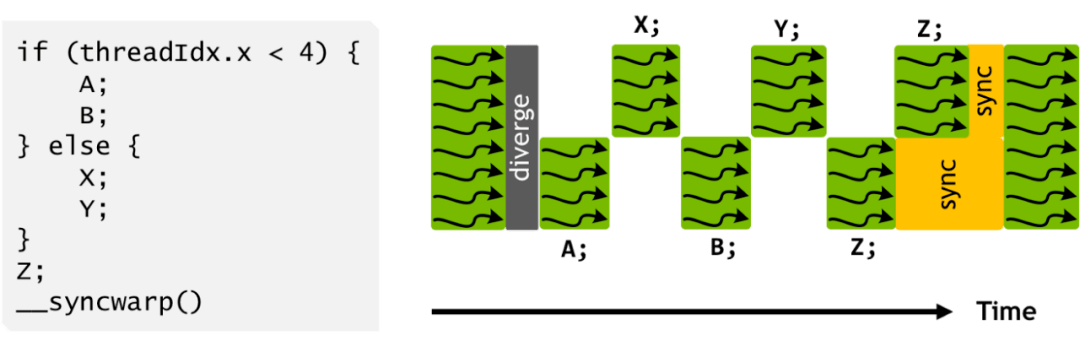
文章图片
SIMT 执行模型 。 图源:英伟达
GPU 遵循单指令多线程 (SIMT) 的编程模型 , 其中相同的指令在不同的内核 / 线程上并发执行 , 每条指令都按照其分配的线程 ID 来执行数据部分 。 所有内核都以帧同步(lock-step)方式运行线程 , 这极大地简化了控制流 。 另一方面 , SIMT 在概念上仍然是一个多线程类 c 的编程模型 , 它被重新用于 AI , 但它并不是专门为 AI 设计的 。 由于神经网络应用程序和硬件处理都可以被描述为计算图 , 因此拥有一个捕获图语义的编程框架会更自然、更有效 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。