文章图片
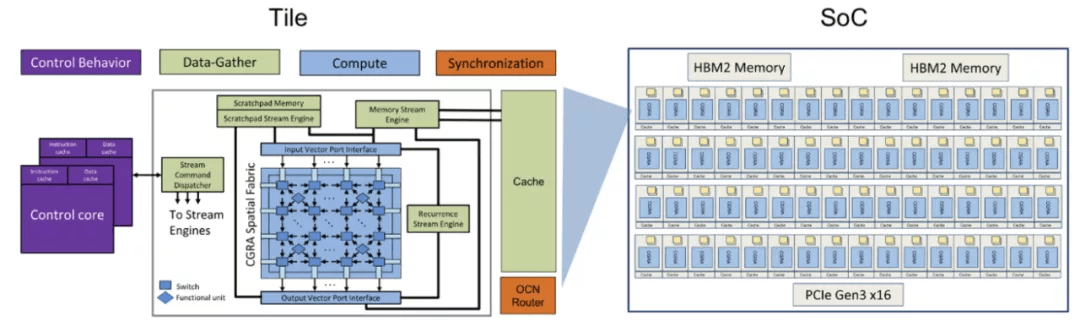
SimpleMachines 的 Mozart 芯片 。 图源:SimpleMachines
该公司的首个 AI 芯片是 Mozart , 该芯片针对推理进行了优化 , 在设计中使用了 16 纳米工艺 , HBM2 高带宽内存和 PCIe Gen3x16 尺寸 。 2020 年 , SimpleMachine 发布了第一代加速器 , 该加速器基于 Mozart 芯片 , 其由一个可配置的 tile 数组组成 , 它们依赖于控制、计算、数据收集等的专业化 。
脉动阵列 + VLIW: TPUv1、Groq、Habana
TPU
世界上首个专门为 AI 量身定制的处理器之一是张量处理单元(TPU) , 也称张量处理器 , 是 Google 开发的专用集成电路(ASIC) , 专门用于加速机器学习 。 自 2015 年起 , 谷歌就已经开始在内部使用 TPU , 并于 2018 年将 TPU 提供给第三方使用 , 既将部分 TPU 作为其云基础架构的一部分 , 也将部分小型版本的 TPU 用于销售 。
文章图片
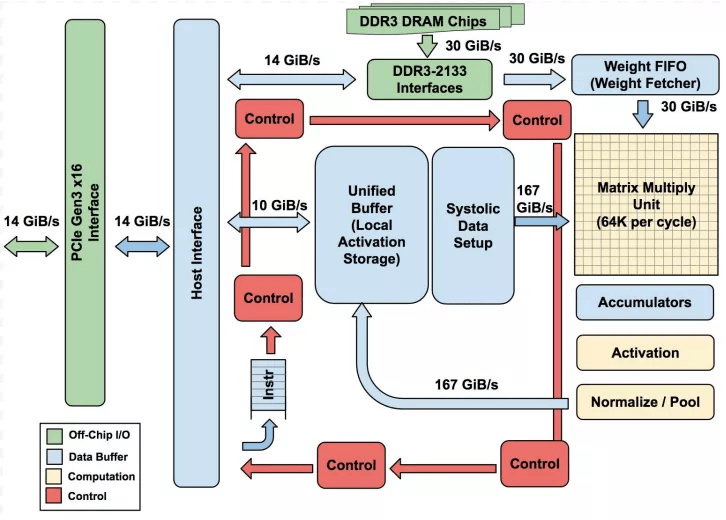
第一代 TPU 体系架构 。 图源:arXiv
第一代 TPU 是一个 8 位矩阵乘法的引擎 , 使用复杂指令集 , 并由主机通过 PCIe 3.0 总线驱动 , 它采用 28 nm 工艺制造 。 TPU 的指令向主机进行数据的收发 , 执行矩阵乘法和卷积运算 , 并应用激活函数 。
第二代 TPU 于 2017 年 5 月发布 , 值得注意的是 , 第一代 TPU 只能进行整数运算 , 但第二代 TPU 还可以进行浮点运算 。 这使得第二代 TPU 对于机器学习模型的训练和推理都非常有用 。 谷歌表示 , 这些第二代 TPU 将可在 Google 计算引擎上使用 , 以用于 TensorFlow 应用程序中 。
第三代 TPU 于 2018 年 5 月 8 日发布 , 谷歌宣布第三代 TPU 的性能是第二代的两倍 , 并将部署在芯片数量是上一代的四倍的 Pod 中 。
第四代 TPU 于 2021 年 5 月 19 日发布 。 谷歌宣布第四代 TPU 的性能是第三代的 2.7 倍 , 并将部署在芯片数量是上一代的两倍的 Pod 中 。 与部署的第三代 TPU 相比 , 这使每个 Pod 的性能提高了 5.4 倍(每个 Pod 中最多装有 4,096 个芯片) 。
Groq
谷歌在云产品中提供了 TPU , 他们的目标是满足谷歌的 AI 需求并服务于自己的内部工作负载 。 因此 , 谷歌针对特定需求量身定制了 TPU 。
2016 年 , 一个由 TPU 架构师组成的团队离开谷歌 , 他们设计了一种与 TPU 具有相似基线特征的新处理器 , 并在一家名为 Groq 的新创业公司中将其商业化 。
文章图片
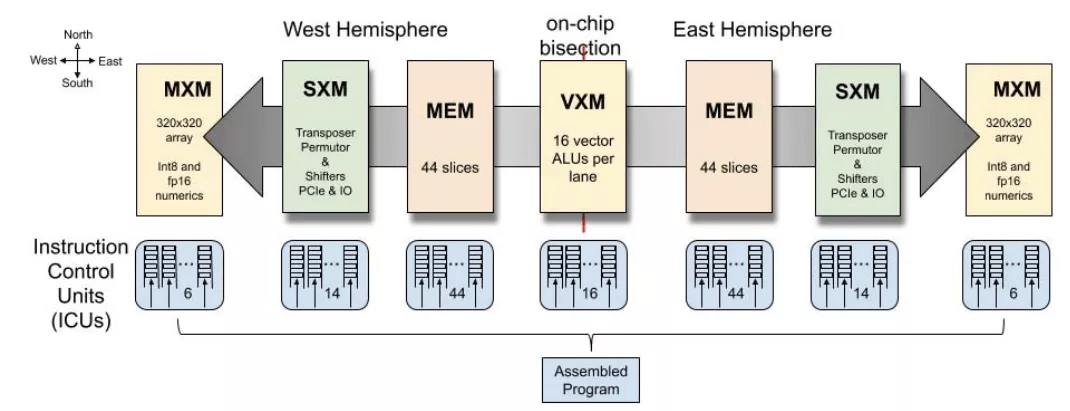
Groq TSP 执行框图 。 图源:Groq
Groq 的核心是张量流处理器(TSP) 。 TSP 架构与 TPU 有很多共同之处:两种架构都严重依赖脉动阵列来完成繁重的工作 。 与第一代 TPU 相比 , TSP 增加了向量单元和转置置换单元(在第二代和第三代 TPU 上也可以找到) 。
文章图片
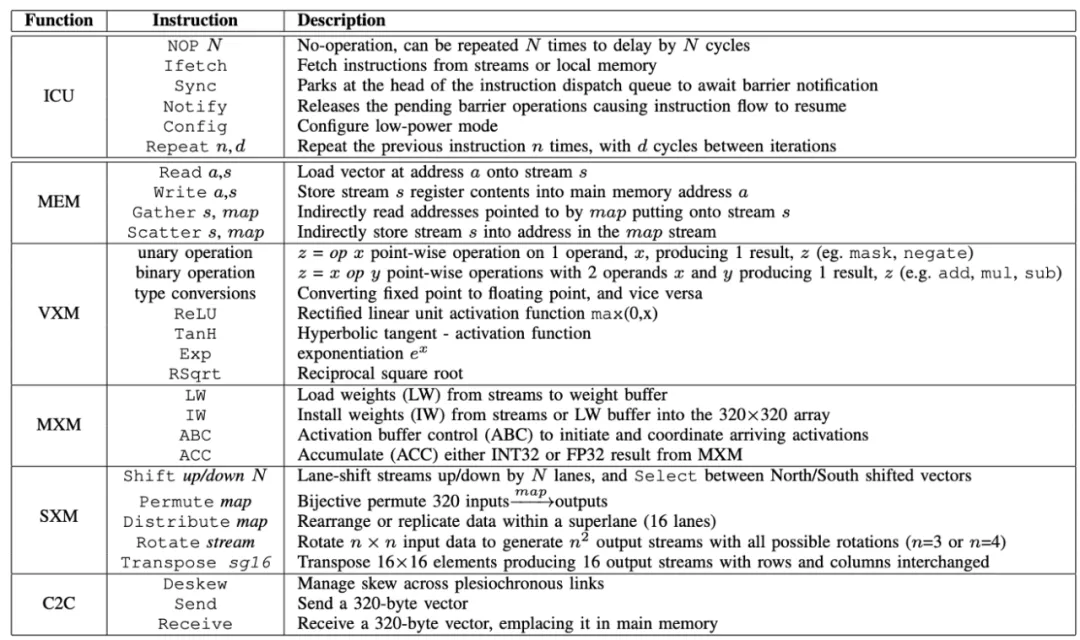
Groq VLIW 指令集和描述 。 图源:Groq
Habana
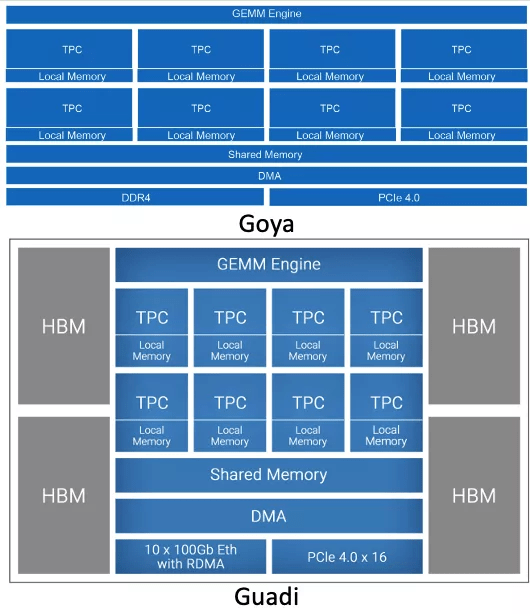
Habana 成立于 2016 年初 , 是一家专注于数据中心训练和推理的 AI 加速器公司 。 Habana 已推出云端 AI 训练芯片 Gaudi 和云端 AI 推理芯片 Goya 。
Goya 处理器已实现商用 , 在极具竞争力的包络功率中具有超大吞吐量和超低的实时延迟 , 展现出卓越的推理性能 。 Gaudi 处理器旨在让系统实现高效灵活的横向、纵向扩展 。 目前 Habana 正在为特定超大规模客户提供样品 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。