文章图片
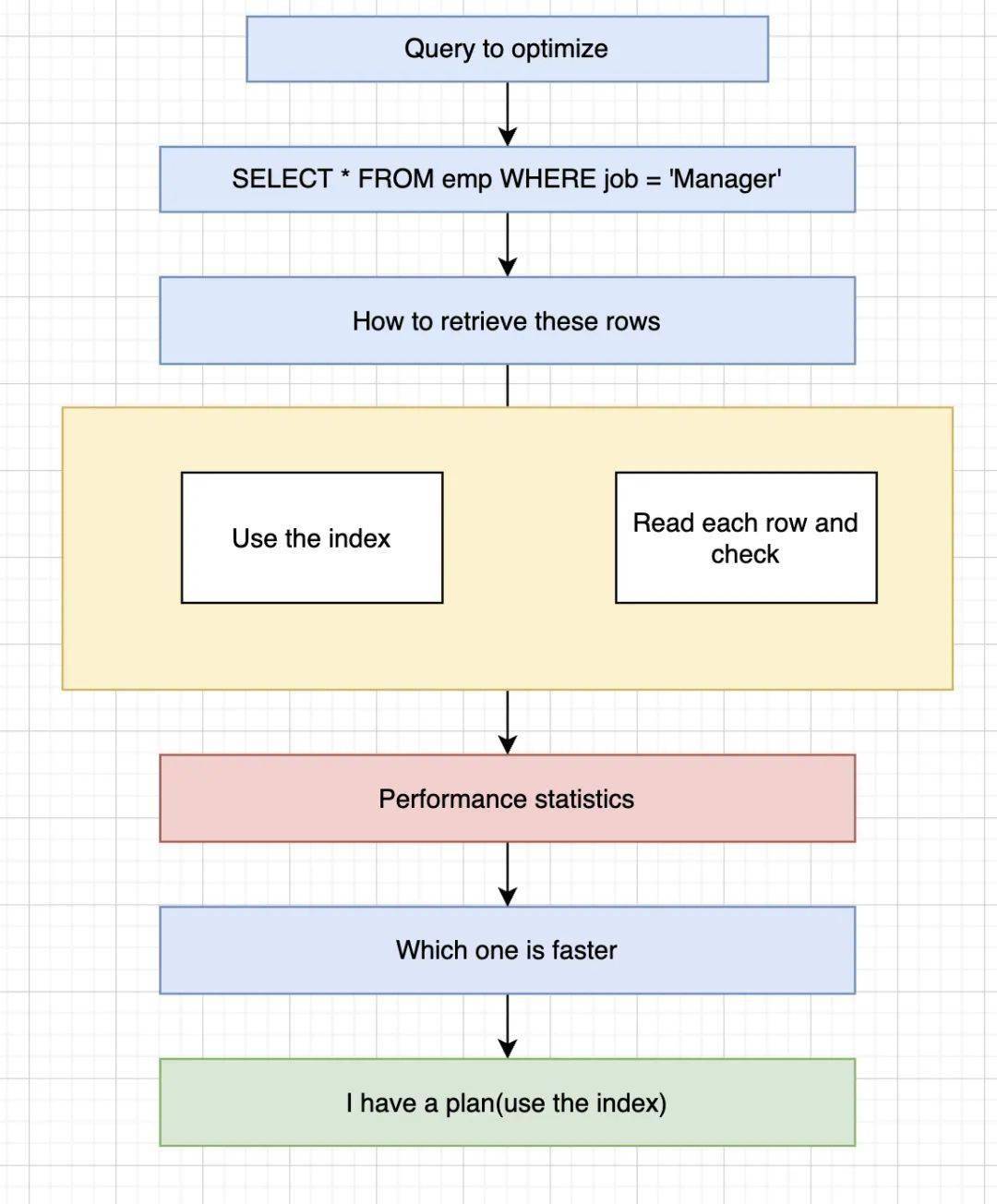
当然 , 这部分工作可以有相对简单的实现(基于规则) , 比如太太说了 , 时间确定、飞机来回、五星酒店、带私人沙滩 。 这样计划就会简单很多 , 也可以复杂到难以想象(基于机器学习、基于实际开销等等) , 太太说你全权负责 , 具体时间不确定 , 大概在8月-9月 , 要少花钱多办事 , 多做调研 , 找一个最优方案 。 那么做这个计划就会非常复杂 , 需要的支持决策信息就会非常多 。 这样做出来的决策大概率相对会优化 , 比基于规则实现的计划能适应更多场景 。
c. 执行模块
优化器做好了执行计划后 , 接下来就会有执行的模块按照执行计划对数据进行相关的计算 , 包括数据的存取、常规的加减乘除、排序、平均值、哈希 , 也会包括一些机器学习的算法 , 数据的压缩/解压缩 , 最后将计算完成的结果返回给客户端 。
文章图片
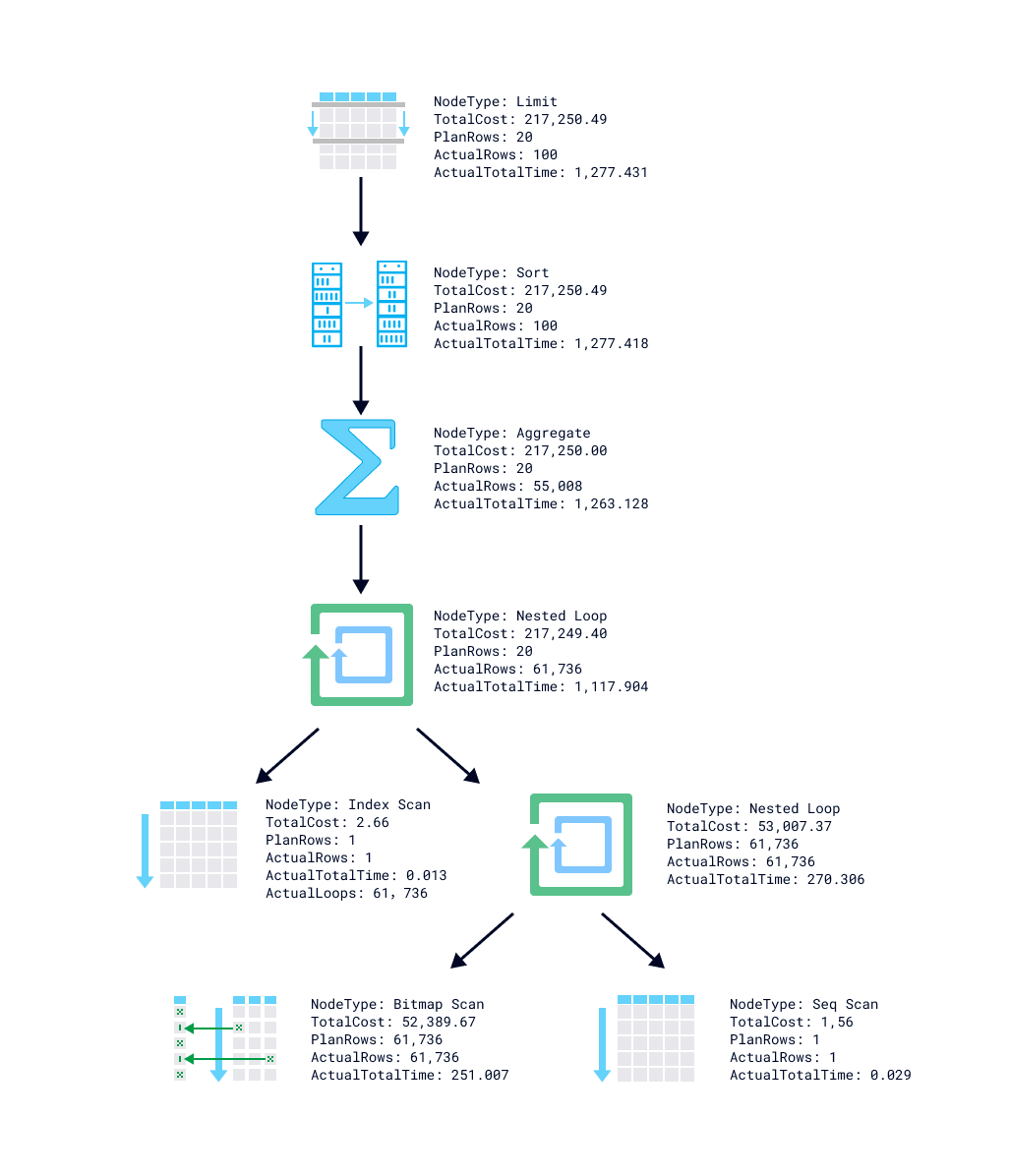
d. 内部管理和调度
数据库要正常的工作 , 还会需要一些内部协调管理的模块 , 比如 , 内存和存储同步 , 存储空间整理 , 元数据管理 , 集群状态检测 , 容错和故障恢复等 。
e. 管理工具和接口
为了提高易用性 , 数据库都需要提供一套管理工具 , 比如备份/恢复、状态检测、运行时监控、资源隔离、权限管理、安全审计、自定义接口、各种数据访问接口等 。
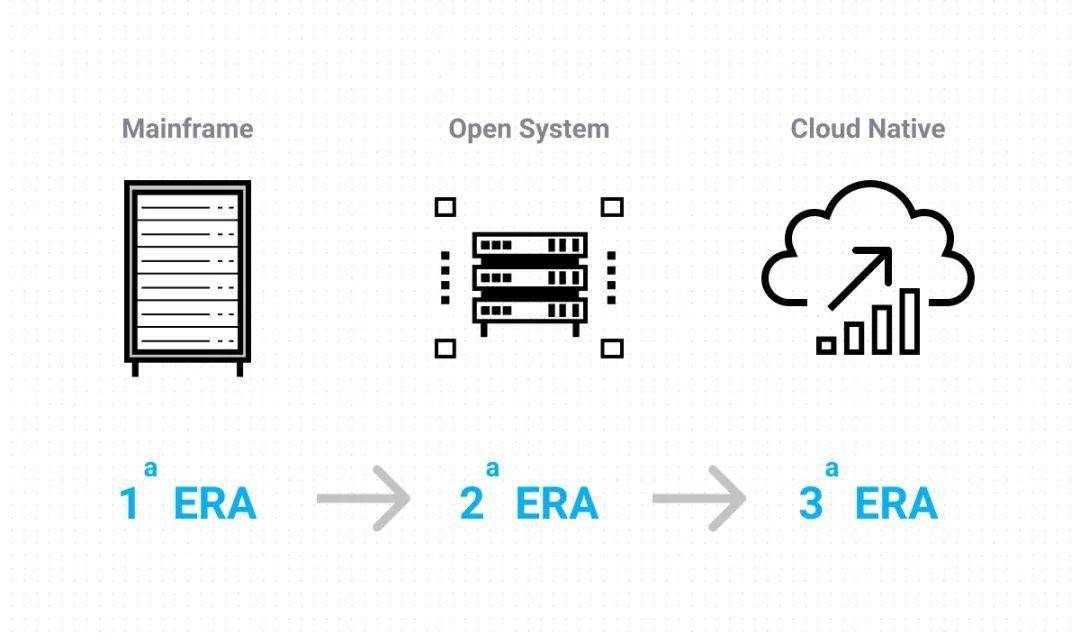
数据库发展和展望
数据库的发展是伴随着计算机体系架构的发展而不断演进的 , 从主机 , 到个人电脑+网络(x86) , 到现在的云服务 , 数据库也经历了一系列的演化历程 。
文章图片
a. 主机时代
最初的计算机和数据库只是在航空航天、军事领域使用 , 只需要支持专业的数据分析人员进行数据分析 。 到了上世纪70年代末 , 伴随着计算机进入更多的商业场景 , 产生了大量的数据分析的需求 , 数据库就需要面对更为普遍的用户需求 。 在IBM最早发布的关系型数据库的论文中 , 最强调的一点就是希望能够让数据库的用户不用再去操心数据应该如何存储和组织 , 而能够高效率使用这些数据进行分析 。
为了方便用户的使用 , SQL(结构化查询语言)被定义了出来 , 按照这样的语法 , 数据库用户只需要关注数据该如何分析 , 不需要关注底层的数据分布和存储等 。
为了要支持大量用户的并发数据操作 , 数据库事务特性被定义了出来 , 保证在并发的数据操作下 , 用户能够看到符合业务逻辑的数据内容 。
为了保证数据库的高效率和安全性 , 数据库重做日志(事务日志)被设计出来 , 包括当前数据库中经常出现的一系列概念 , 比如回滚日志(Undo Log)、提交日志(commit log)、检查点(checkpoint)等等 。
主机时代由于硬件成本极其昂贵 , 不论是存储、内存还是CPU资源 , 相对来说都很稀缺 , 那么数据库在设计和使用上就会采用各种算法和架构来降低对内存的使用 , 减少数据的冗余 , 提高数据的检索效率 , 因此各种数据索引类型 , 功能强大的查询优化器 , 数据缓存算法等在数据库中得到了极大的发展 。 同时在使用数据库时 , 也要对数据进行各种复杂的模型设计(3范式模型 , 星型模型 , 雪花型模型等等)以降低数据的冗余程度 , 当然这样也会增加数据库应用的开发难度 。
b. x86时代
伴随着x86服务器的广泛使用和网络技术的发展 , 把N台x86服务通过网络组建成一个集群 , 利用这个集群的计算、存储能力来取代昂贵的主机也就更加具有性价比 。 在这种趋势下 , 也就设计出了各种能够使用集群能力的分布式数据库系统 , 这些系统的核心思想就是把数据分散在不同的节点上 , 利用多个节点的计算和存储资源提高对数据的存储和分析能力 。 在分布式的处理架构下 , 数据一致性协议、多副本机制、高可用机制、数据分片机制、扩容/缩容机制等等也都成为了分布式数据库必须要设计和解决的问题 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。