文章图片
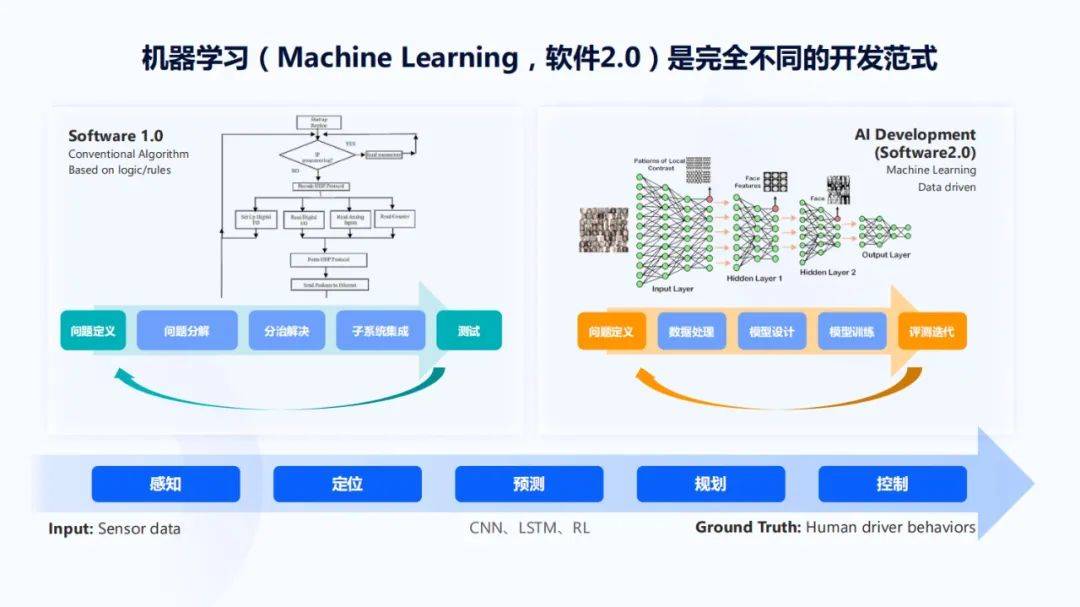
软件2.0时代的方法可以让机器像人一样看懂和听懂周围的世界 , 所以它有广泛的应用场景 , 而且随着摩尔定律的持续进步 , 有非常大的成长空间 。 关于自动驾驶芯片的好用 , 也应该围绕着软件2.0的开发范式展开 , 因为1.0时代已经有四五十年的积累 , 各种工具已经非常完善 , 在此基础上更多的是一些微创新 , 而2.0时代则是一种底层方法论层面的颠覆式创新 。
在这套开发范式下 , 对于机器来说 , 软件2.0的技术可以让它感知周围的世界 , 知道自己在世界里处于什么位置 , 当世界里有很多自主移动的目标时 , 可以预测周围的目标的运动轨迹 , 可以规划自身的动作是绕开目标 , 还是直着前进或停下来 , 进而控制自己完成动作 。
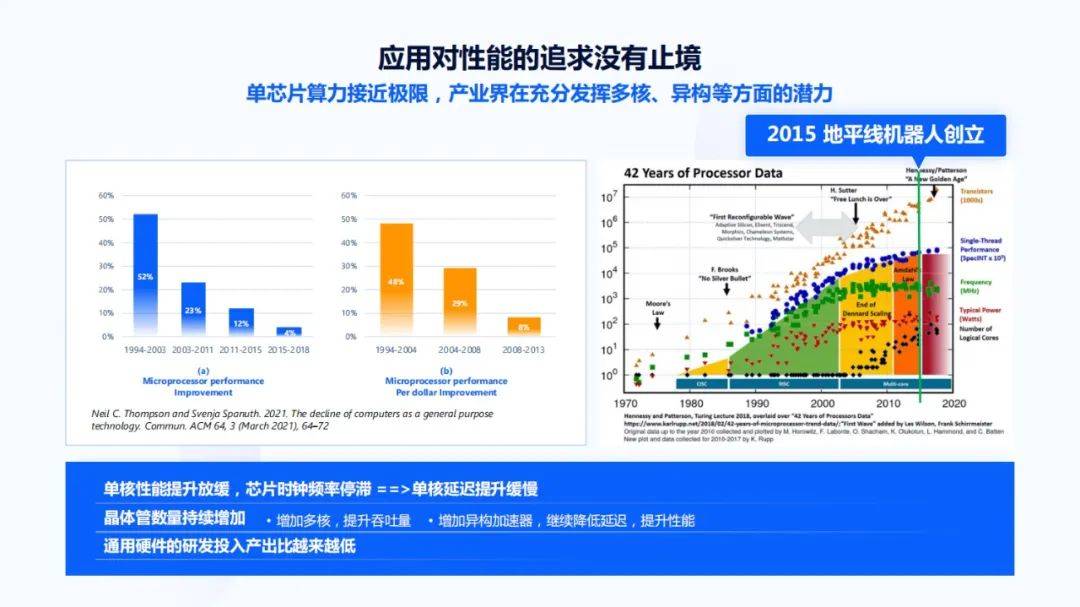
1.关注软硬结合前提下的软硬解耦首先回顾下历史 , 在看历史时会发现一个很重要的点是“应用对性能的追求没有止境” 。 在这种情况下 , 很多芯片一代一代的往前走 。 从1970年开始 , 各种各样的芯片、计算设备层出不穷 , 也造就了很多PC时代 。
文章图片
上图左边的蓝色统计表来自于2021年ACM通讯的一个统计结果 , 该图表明在过去的20多年里 , 微处理器性能的提升在逐渐放缓 。 同时站在供应商的角度 , 从黄色统计表中可以看出 , 单位研发投入下微处理器的性能提升也在逐渐变小 , 所以未来在通用处理器上的研发投入产出比会越来越低 。 越来越多的公司会把更多精力投在多核和异构加速器上 , 右图就是一个很好的证明 。
由于人们对性能的追求没有止境 , 单个芯片上的晶体管数量会呈指数级增长 。 而单个线程的性能 , 在2010年左右逐渐放缓 。 因为物理条件的限制 , 频率也不再增长 , 并随着工艺制成的变化 , 整个芯片的功耗也处于一个停滞的状况 。 与此同时 , 单个芯片里的逻辑处理器核心变得很多 , 这会导致我们在追求非常高延迟增强时 , 由于单线程的性能没有大的变化 , 使得我们无法通过单线程的通用处理器达到很好的效果 , 只能把代码做并行 , 或引入异构加速器来实现性能优化 。

文章图片
虽然单个线程的性能处于增长缓慢甚至停滞的状态 , 但在软件和算法层面 , 还有非常多的空间可以做优化 。 上图上半部分是对矩阵乘例子的优化 。 当我们用Python实现矩阵乘时 , 假设它的速度为1 , 把 Python代码改成Java或C时 , 可以看到有11倍甚至47倍的提升 。 这是语言之间的变化 , 只是用不同的编程语言改写 , 与芯片架构无关 。 之后的循环并行利用到芯片上的多核;并行分置则是把矩阵分块 , 然后放在缓存里;再用自动向量化 , 自动化的利用芯片里已经提供的数据流并行CMD指令;当使用较宽的AVX向量时 , 在代码里面直接写AVX函数调用 , 最多可以得到6万多的加速比 。 所以 , 当我们围绕软件和算法的特点挖掘更多硬件特性时 , 就能通过这种软硬结合的方式获得非常大的性能提升和极具性价比的计算平台 。
最近 , 有件有意思的新闻 , Intel在新的大小核架构中 , 为了保证软件兼容性 , 放弃了部分芯片中AVX512支持 。
接下来看下软硬结合和软硬解耦过去在整个技术栈中是怎样做的?当我们看标准的C和C++代码时 , 这与芯片无关 , 可以实现软硬解耦 , 它是怎么做到的呢?我们以LLVM编译器为例 , 编译器里有前端、中端和后端 , 其中前端和中端里有很多的代码分析、优化和变换 , 这些都与芯片架构无关 。 编译器后端也有与芯片有关的部分 , 像ARM后端和RISC-V后端 , 通过这些之后 , 编译器可以把代码变成可执行文件 , 这些可执行文件可以部署在ARM芯片或RISC-V芯片上运行 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。