2月23日 , 地平线在智东西公开课开设的「地平线AI芯片技术专场」第2讲已顺利完结 , 由地平线高级研发总监凌坤主讲 , 主题为《好的自动驾驶AI芯片更是“好用”的芯片》
凌坤老师从软件2.0的开发范式讲起 , 结合地平线自动驾驶AI芯片的开发实践 , 从软硬结合+软硬解耦的平衡、AI芯片开发原则、软件2.0开发范式的基础设施艾迪AI开发平台、天工开物工具链、丰富的软件栈等方面深入讲解如何打造一颗“好用”的自动驾驶AI芯片 。
首先欢迎大家来到本次课程 , 也感谢智东西公开课提供的平台 , 让我们有机会做相关的交流 。 上次课程中地平线罗恒博士重点讲解了一个好的自动驾驶芯片应该是什么样子 , 今天则是关于怎么样把自动驾驶芯片做成一个好用的芯片 。

文章图片
我叫凌坤 , 地平高级研发总监 , 毕业于中国科学院计算技术研究所 , 十余年专注于CPU/DSP/DSA上的编译器&指令架构联合优化和实现;2016年加入地平线 , 负责地平线天工开物工具链和艾迪AI开发平台相关研发团队的管理;曾任地平线编译器研发部负责人 , 先后参与多代地平线征程处理器的指令集架构定义、编译器和工具链研发、产品化、市场推广及量产落地相关工作 。
本次课程主要分为以下3个部分:
1、关注软硬结合前提下的软硬解耦
2、好用的关键:提升产品研发效率
3、用软件2.0基础设施、工具链、开放软件栈和丰富样例成就开发者
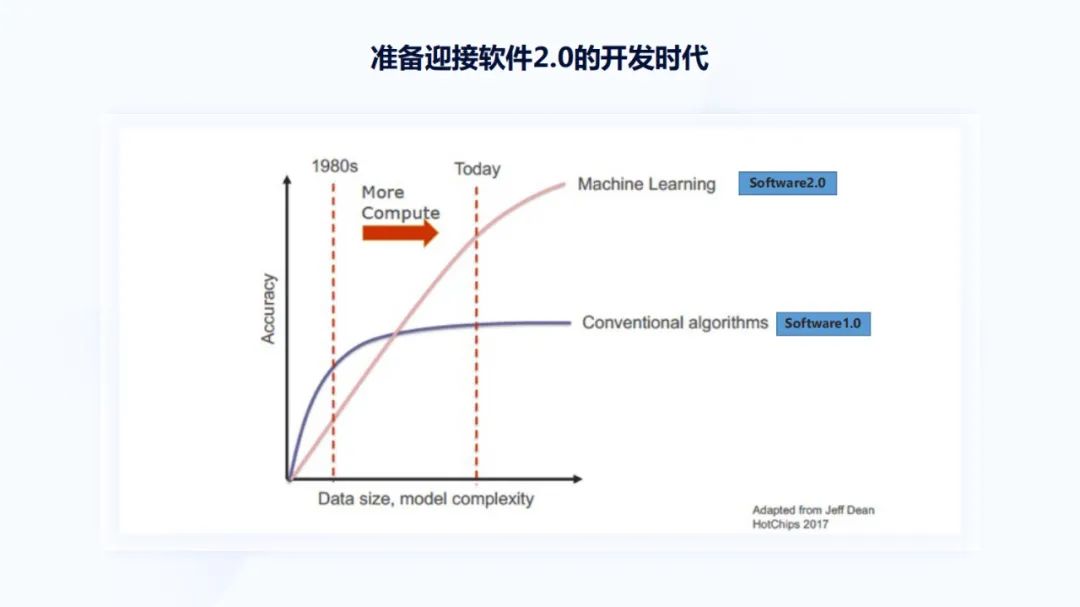
过去很多年里 , 我们一直在做传统意义上的算法和软件研发 。 在这套体系下 , 程序员首先要理解清楚问题是什么?怎么解?在此基础上写好代码 , 并让代码运行起来 , 看是否正确 。 而随着芯片性能越来越高 , 存储数据、模型容量越来越大 , 机器学习方法帮助我们解决了许多实际的问题 , 因此进入到软件2.0时代 。 伴随着未来摩尔定律的持续演进 , 基于软件2.0的研发工作会越来越多 , 我们要准备好迎接软件2.0的开发时代 。
文章图片
回看软件2.0的开发范式 , 它与软件1.0完全不同 。 在软件1.0中 , 当我们要解决一个问题时 , 首先需要开发者把问题定义的十分清楚;然后把问题分解成具体步骤 , 并把每一步的解决方法也想的非常明白;再写出代码 , 代码做好测试后集成起来 , 看能否解决实际问题 。 如果不能解决 , 反过来再看 , 是问题没有定义清楚?问题没有分解清楚?问题的解决方法不正确?还是程序员代码没写好?反复检查、调试、验证 , 以上就是软件1.0开发的闭环迭代过程 。 例如当控制一辆车往前走时 , 如果路上没有超过限速 , 前方没有障碍物 , 那接下来车辆可以加速 , 加速到多少时不能再加速 , 这是一个典型的 if-then-else问题 , 所以整个软件1.0时代的代码程序都是围绕 if-then-else、 for循环函数等典型的概念展开 。
当到了软件2.0时代 , 面临的是一个完全不同的开发模式 。 首先需要定义问题 , 同时需要大量的数据 , 数据用来表示几种不同的情况;然后再设计一个适当的模型 , 模型能够对问题做分类或检测;之后在大量标注数据上做模型训练 , 训练完成后再部署集成 ,在场景中看大概有多少结果是正确的 , 多少结果是错误的;再持续的采集数据 , 做标注、训练 , 或者更改模型的设计 , 来解决这些错误的badcase 。
在过程中 , 没有一个程序员能把问题解法想得十分清楚 。 比如识别一只猫 , 猫的毛发是弯的还是直的、猫的颜色是花的还是纯色 , 猫的两只耳朵是竖着的还是弯着的 , 程序员并不是通过这种方式解决问题 。 从每一个像素点定义的角度来看 , 这些问题是一个数据驱动的问题 , 即通过100万张或1000万张不同的图片给模型做训练 。 在这种模式下 , 程序员不需要对问题应该怎么解有非常深刻的认识 , 也不需要知道计算机每一步该怎么操作 , 只需关注卷积神经网络的容量和里面的信息 , 反向传播时梯度是怎样传播的 , 激活函数应该怎么设置等问题 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。