对比Intel AVX禁用的消息 ,在最新的ARM处理器架构上 , 引入了一个SVE向量处理单元 , 它可以用来取代NEON 。 NEON是在 ARM架构上的一个SIMD扩展指令集 , 它类似于AVX的单指令多数据 , 但NEON是定宽的 , 即128比特 。 SVE则是变长的 , 它可以实现128比特、256比特和512比特的宽度 。 在性能评估上 , 最高可以获得3.5倍的加速比 。 在SVE指令集层面并没有详细规定{128、256、512} , 它是在具体芯片实现时 , 硬件可以自己定一些常数来做 , 而所有的指令都是通过自己判断或者加入一些参数的方式进行 , 可以不考虑向量的实际宽度 , 即在相同的指令下 , 既可以在128比特宽度下执行二进制代码 , 也可以在256比特或512比特宽度下执行二进制代码 , 不会出现英特尔AVX512的情况 。 所以ARM在数据并行方面 , 在二进制代码兼容性的思考是比较超前的 , 它在想办法规避掉问题 , 保持二进制兼容 , 通过这种方式能很好的支持底层晶体管为上面的服务 , 同时保持好软硬解耦 。
刚刚讲到了C和C++ , 在真正面向AI时代时 , 不得不提到GPU , 即CUDA 。 利用GPU里大量并行的单指令多线程架构 , 可以实现非常复杂的数据流并行运算 , 进而加速上层的张量计算 , 来获得比较好的 AI性能加速 。
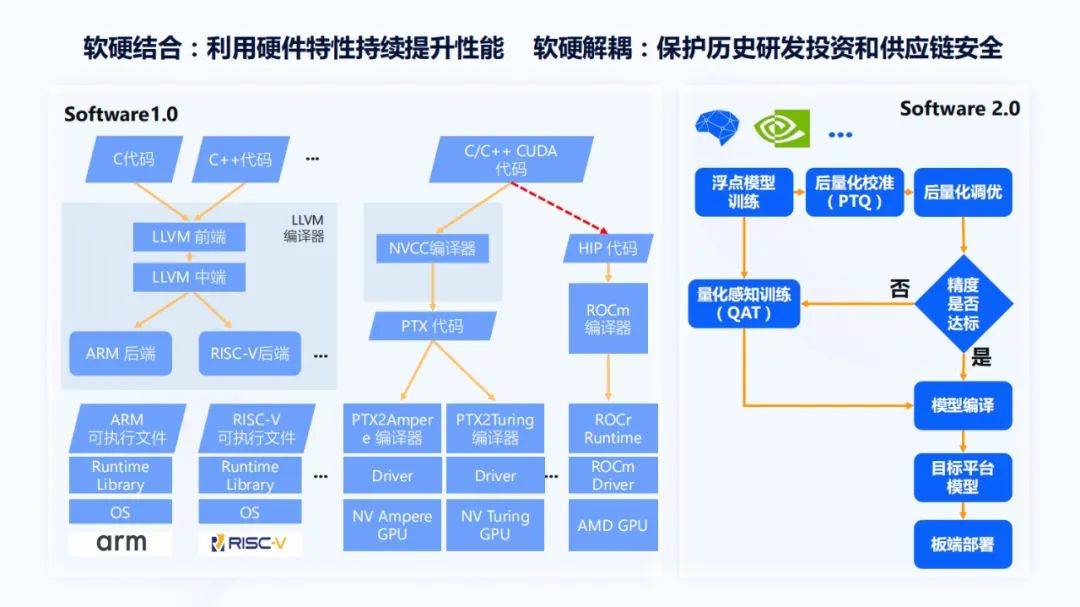
这里很典型的CUDA是英伟达提出来的 , 它通过NVCC编译器变成PDX代码 , PDX代码在各代GPU上都会有自己的PTXToGPU编译器 , 再通过驱动就可以在Ampere架构GPU或Turing架构GPU上运行 。 在过去的很多年里 , 英伟达在这方面有非常多的积累 , 而且形成了比较强的市场主导地位 。
在AI时代 , 英伟达基本上是在唱主角的 , 虽然AMD最近市值有了比较大的提升 , 但AMD对AI方面的知识一直处于被动的状态 。 最近AMD比较大的动作是提出了ROCm编译器 , 虽然没有明确的介绍 , 但可以认为它是为了更好的兼容CUDA生态 , 所以它会把CUDA代码先通过一个转换器转成HIP代码 , 再通过ROCm编译器 , 最后在AMD的GPU上运行 。
文章图片
上图右部分画了虚线 , 这是由于当我们决策是买英伟达GPU , 还是买AMD GPU做AI计算加速时 , 大部分的开发者都会去选择英伟达 , 因为不用担心编译器或Runtime的问题 , 或者有些bug没有被测到 , 进而导致生产效率受到很大影响 , 所以右边用了虚线 。 这条线虽然存在 , 但是好与坏 , 很多的用户和开发者都已经用脚在投票 , 这是一个典型的软硬结合和软硬解耦不易做到权衡的问题 。 而且在英伟达的历代GPU上可以通过PTX代码实现比较好的软硬解耦 。 同时 , 软硬结合就体现在了NVCC编译器和CUDA对芯片架构的深层次挖掘和利用上 , 上面是软件1.0 。
再来看软件2.0 , 它的整个开发流程大概分成以下几个阶段:先对一个模型进行训练 , 之后做量化 , 因为量化能带来芯片功能和效能的提升 , 再来看精度是否达标 , 然后做模型编译到芯片平台上运行 。 上述这些步骤 , 包括地平线在内 , 大部分芯片厂商都可以做到比较好的软硬解耦 。 通过这种形式的软硬解耦能够保证开发者过去写的一些历史研发代码可以在平台上更好的运行 , 同时也能保证一定的供应链安全 。
刚刚在回顾历史 , 而面向 AI计算的软硬件设计还需要一个比较完整的工程架构来保证 。 首先要有性能 , 在此基础上 , 再来看怎么样做好软硬件解耦 。 结合地平线的实践 , 一般情况下会从硬件设计和软件设计两个层面来看 , 硬件设计主要针对存储、张量计算组织、指令集设计 , 软件方面包括计算分析和并行优化、数据并行和依赖分析优化、片上存储管理和指令调度 。 它们的核心目标是为了能够最大化硬件资源的利用率 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。