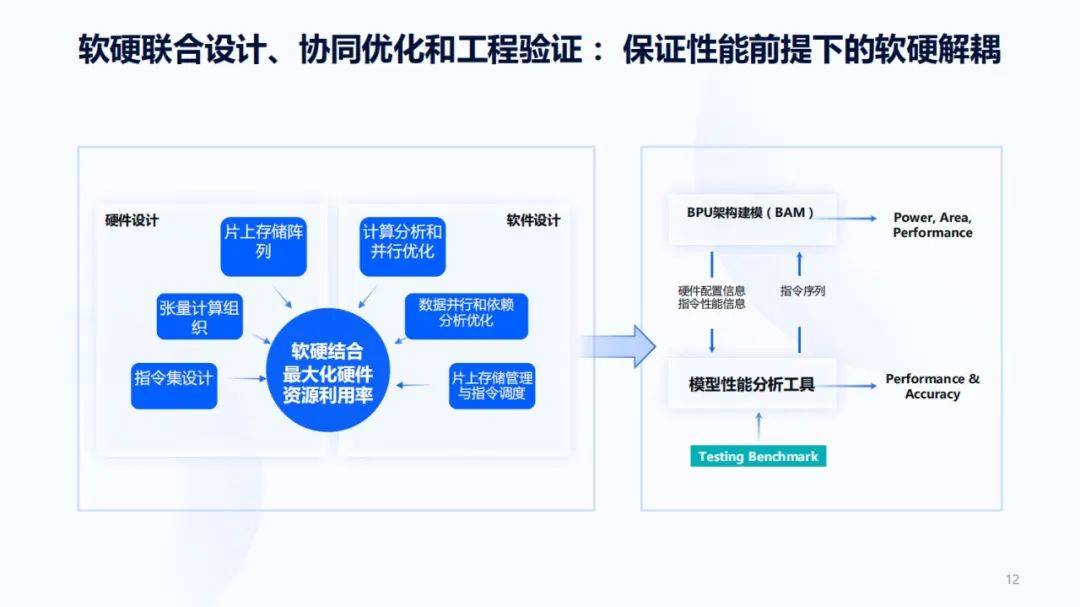
为了保证未来持续的竞争力 , 需要更多的晶体管来做更多的事情 , 但是这些晶体管到底用来做什么?怎么样保证最大化利用好这些资源 , 为上层AI算法和应用提供足够多的AI计算能力 , 就需要软硬结合的一整套工程迭代框架 。
地平线有一个BPU架构建模工具 , 它可以对功耗、性能、面积做建模 , 输入的是指令序列 , 建模工具为模型性能分析工具提供了一些硬件配置信息和指令性能信息 。 模型性能分析工具则提供了性能和精度方面的分析结果 , 同时为BPU架构建模提供输入 。 BPU架构是在探索未来的芯片架构 , 模型性能分析工具则在探索接下来的编译器、模型量化工具、训练工具应该怎么做 。 它们有个很重要的输入:Testing Benchmark 。 如果Testing Benchmark没选好 , 整个闭环会转歪 , 所以 Testing Benchmark选取十分重要 。
文章图片
Testing Benchmark的选取一定要把握好算法演进趋势 , 由于Benchmark里面包含了丰富的、代表未来演进趋势的算法模型 , 利用好Benchmark和相关变换之后 , 就能更好的平衡软硬结合和软硬解耦 。 像地平线已经达到百万芯片出货量的征程二代和征程三代芯片里就有比较多的设计 , 在2016年、2017年时已经考虑到了相关一些算法的演进趋势 。
地平线就有一个非常强大的算法软件团队 , 这个团队不停的去看、去听或去实践算法的实际应用情况 , 及未来的演进趋势 , 更好的为Testing Benchmark提供输入 。
文章图片
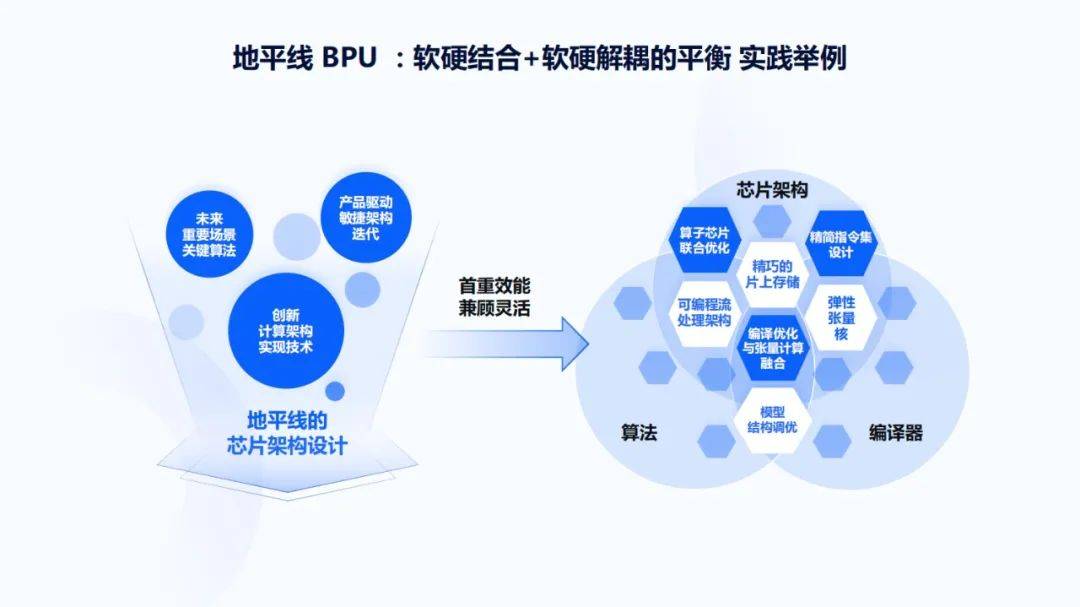
接下来将结合地平线的实际情况进行说明 , 希望可以给大家一些新的启发 , 或带来一些不同的观点和角度 。 在地平线的芯片架构设计中 , 包括Testing Benchmark的选取 , 面向的都是未来重要场景里的关键算法 , 而且一定要在产品驱动里做架构迭代 , 要看产品里模型的泛化性怎样 , 模型实际应用起来运行的如何 , 它对哪些目标能够识别的很好 , 哪些还有问题 , 把这些点在产品层面尽量挖掘出来 , 然后在产品驱动敏捷架构迭代和未来重要场景关键算法两个层面的结合下形成Testing Benchmark 。
同时 , 地平线有很多世界领先的专家团队 , 他们结合过去几十年在计算架构、软件、硬件、芯片和算法方面的积累 , 预判在AI计算层面还有哪些工作可以做相关的优化和创新 。 这里首先看重效能 , 并要兼顾灵活 , 具体会从芯片架构、算法和编译器三个角度来做 , 而且这三个方面会有很多交叉领域的思维碰撞及工程实践迭代 。 例如当我们看指令集时 , 不仅仅是看RISC-V指令集 , 而是看在编译器眼中张量计算到底是什么 。 在这种情况下 , 我们应该怎么样做指令集 , 弹性张量核、片上存储、可编程流处理架构等这方面有哪些思维碰撞 , 通过这些方面的具体的技术点来给大家一个大概的感觉 , 即软硬结合和软硬解耦在什么样情况下可以找到平衡 。
当我们提到软硬结合和软硬解耦时 , 最终芯片都需要最大化的解放开发者的生产力 , 让他们快速研发产品 。 所以地平线坚持做好自动化工具 , 自动化的利用芯片特性 , 如果芯片特性不能被自动化利用 , 那究竟是工具的问题 , 还是芯片架构设计的问题 , 抑或是算法层面上的问题 , 这些都需要严格的论证 。 在这个情况下 , 我们把工具做好 , 自动化的利用这些特性 , 自动的分析模型 , 分析依赖 , 去变换、提高性能 , 并降低带宽 。
在编译器优化上 , 首先是把张量计算拆分开 , 通过对特征图和卷积kernel的计算拆分 , 编译器可以用更小的粒度描述计算 , 避免引入不必要的依赖 , 提升数据并行性 , 创造潜在的调度机会 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。