文章图片
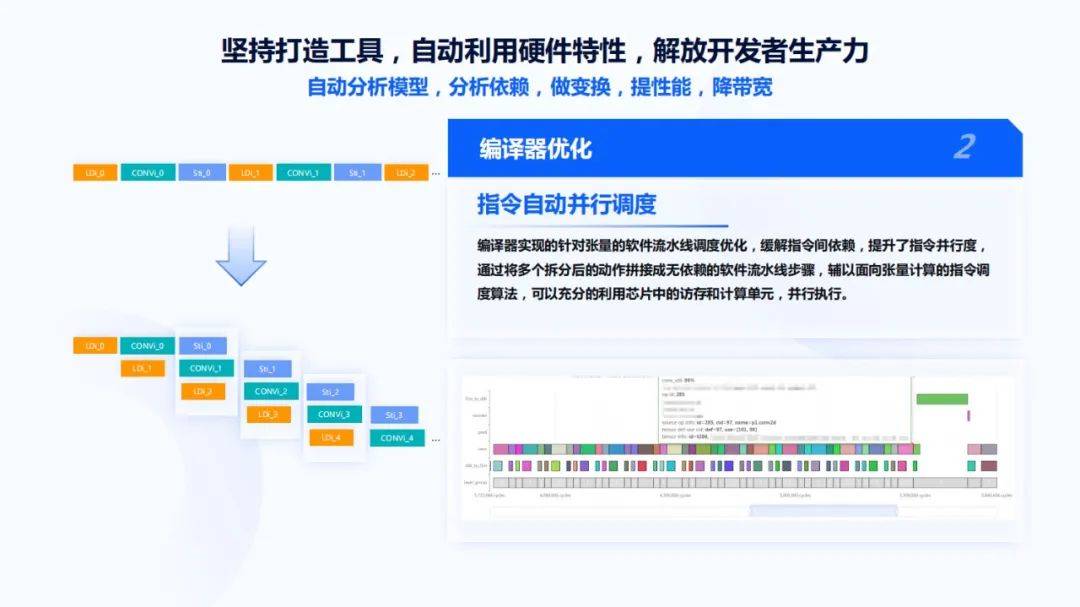
接着是指令调度 , 指定调度也是非常经典的编译器优化方法 , 我们在编译器层面也做了很多工作 。 首先它是张量 , 相对于寄存器来说 , 很大的不同在于张量是变化的 , 它有不同的channel、kernel , 卷积核 。 因此 , 需要对张量数据做建模 , 同时在软件方面要有很强的指令流水线调度 , 即是软流水 。
软流水的流程如左上角图所示 , 做完Load、Conv、Store后 , 再做Load、Conv、Store 。 由于两个Load之间没有必然的联系 , 可以用如左下角图的方式做成流水线 , 可以看到每一组的方块本身就是一个循环体 , 但是循环体内部的三条指令没有必然的联系 , 通过这种方式三个指令就能自由灵活的同时运行 。 右下角图表示一个实际的网络执行过程 , 可以看到卷积阵列基本上是完全排满的 , 没有任何缝隙 。 ddr_load在中间配合着为卷积阵列提供输入 , 同时会有一些别的运算 。 整体上可以获得非常高的卷积利用率 。
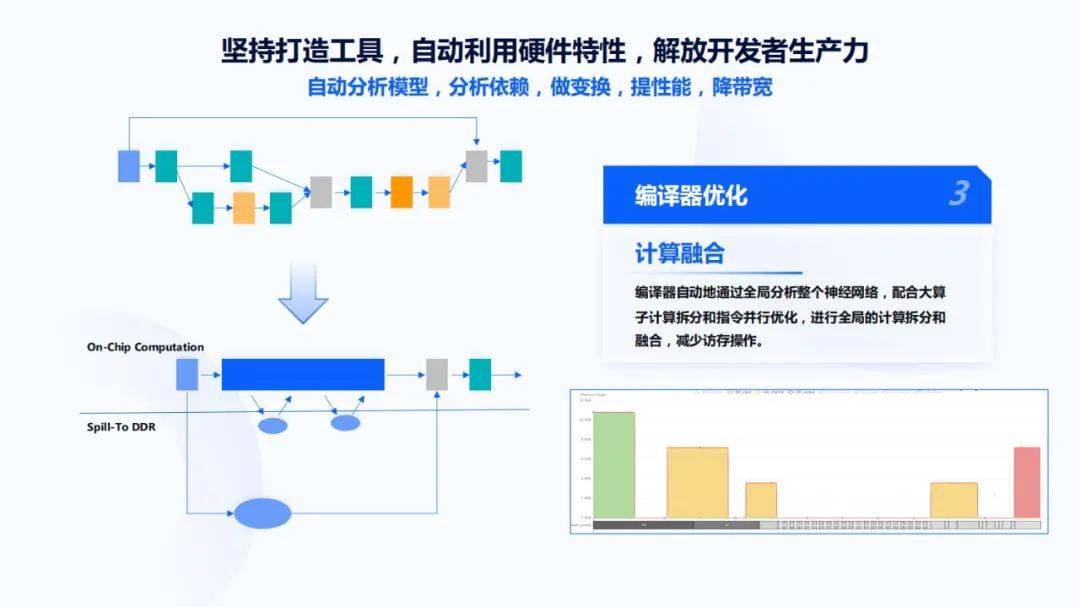
上面是提到了卷积切分和指令调度 , 但很关键的问题是这么多层该怎么样切分?这首先想到了C语言编译器是怎么做的 , 它针对每一个函数内部做分析、编译 , 然后看函数内部的这些代码该怎样做相互之间的优化 。 同理 , 当把卷积神经网络的一次Inference看成一个函数时 , 应该通盘去看函数内部的整个执行过程中计算要怎样去做 。
文章图片
在地平线的实践中 , 我们利用了一套计算融合技术 , 把算子综合去看 。 如上图左边所示 , 把operator整个融合在一起 , 因为片上的memory总是很有限的 , 而且很贵 , 必要时溢出一些数据到DDR里 , 腾出一块片上空间来保证执行可以进行下去 , 这块空间越小越好 , 这样整个DDR的访存带宽可以很小 。
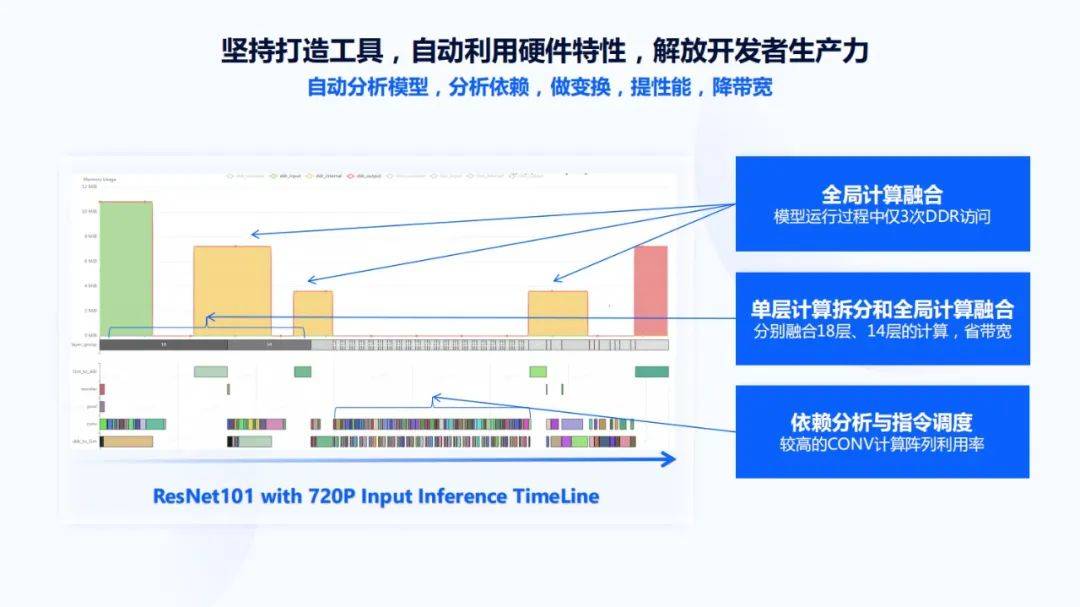
右下角这张图是720p图片输入到ResNet101网络中 , 可以看到开始是先把图片装载到芯片内部 , 然后通过中间的运算 , 再把它存到DDR里 。 中间的过程只有三次DDR的访问 , 这三次实现了一些数据的搬进、搬出 , 前面大概是一个18层的层融合输出 , 再有一个14层的层融合输出 , 最后是一个三层的融合输出 , 通过这种方式可以最小化整个Inference过程中对DDR带宽的访存压力 。 与此同时 , 还可以看片上的memory到底被利用的怎样 , 挖掘接下来memory怎样被利用满 , 是在编译器上优化 , 还是在芯片架构或算法张量大小上做更合理的调整 。
文章图片
上图是把所有的效果放在一起宏观展示 , 可以看到有全局的计算融合 , 单层计算拆分和全局计算融合和依赖分析与指令调度 。
2.好用的关键:提升产品研发效率什么是“好用”?我认为好用是把开发者头脑里对产品的思考 , 利用芯片上所能提供的辅助设施 , 以最快的方式打造出他最想要的产品 , 来提升研发效率 。

文章图片
怎么样提升研发效率 , 也不是一个容易衡量的词 , 所以先看历史 。 上图是过去100年时间里整个计算技术的发展 , 从最早利用机械摇杆的密码破译、线缆插拔的弹道计算 , 到商用计算、办公游戏云服务 , 再到大家比较熟悉的移动通信 , 包括安卓和iOS 。 在此之前都无法绕开图灵机以及控制图灵机的编程模型 , 去实现人们想要机器做的行为 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。