步骤6:将分数乘以值

文章插图
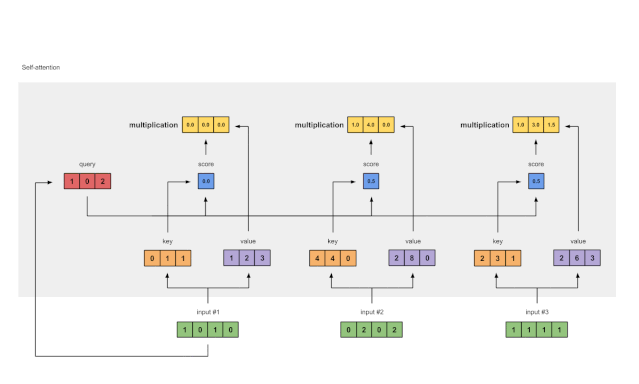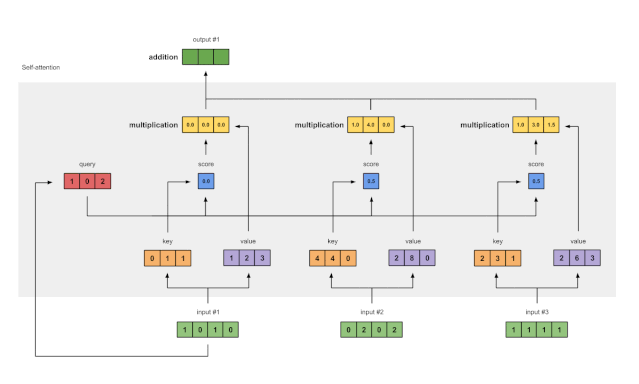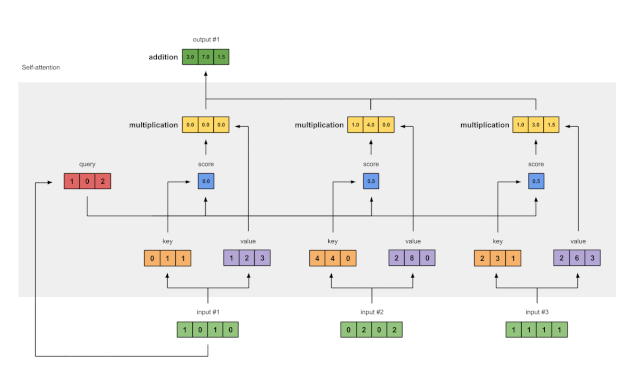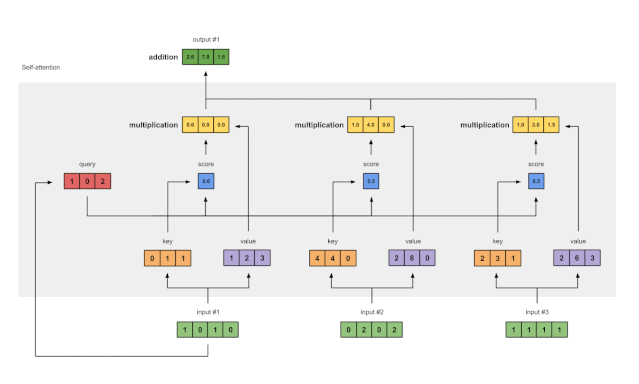
图 1.6:从乘数值(紫色)和分数(蓝色)得出的加权值表示(黄色)
每个经过 softmax 的输入的最大注意力得分(蓝色)乘以其相应的值(紫色),得到 3 个对齐向量(黄色) 。在本教程中,我们将它们称为加权值 。
1:0.0 * [1、2、3] = [0.0、0.0、0.0]2:0.5 * [2、8、0] = [1.0、4.0、0.0]3:0.5 * [2、6、3] = [1.0、3.0、1.5]步骤7:求和加权值以获得输出 1
文章插图
图 1.7:将所有加权值相加(黄色)以得出输出 1(深绿色)
取所有加权值(黄色)并将它们按元素求和:
[0.0,0.0,0.0][1.0,4.0,0.0][1.0,3.0,1.5]-----------------= [2.0,7.0,1.5]所得向量[2.0、7.0、1.5](深绿色)为输出1,该输出基于输入1与所有其他键(包括其自身)交互的查询表示形式 。
步骤 8:重复输入 2 和输入 3
既然我们已经完成了输出 1,我们将对输出 2 和输出 3 重复步骤 4 至 7 。我相信你自己就可以操作 。

文章插图
图 1.8:对输入 2 和输入 3 重复前面的步骤
注意:由于点积分数功能,查询和键的维必须始终相同 。但是,值的维数可能不同于 查询和键 。结果输出将遵循值的维度 。
2.代码这是PyTorch代码(https://pytorch.org/),PyTorch是流行的 Python 深度学习框架 。为了方便使用在以下代码段中索引中的@operator API、.T 和 None,请确保你使用的是Python≥3.6 和 PyTorch 1.3.1 。只需将它们复制并粘贴到 Python / IPython REPL 或 Jupyter Notebook 中即可 。
步骤1:准备输入
import torch x = [ [1, 0, 1, 0], # Input 1 [0, 2, 0, 2], # Input 2 [1, 1, 1, 1] # Input 3 ] x = torch.tensor(x, dtype=torch.float32)步骤2:初始化权重
w_key = [ [0, 0, 1], [1, 1, 0], [0, 1, 0], [1, 1, 0] ] w_query = [ [1, 0, 1], [1, 0, 0], [0, 0, 1], [0, 1, 1] ] w_value = https://www.fult.cn/[ [0, 2, 0], [0, 3, 0], [1, 0, 3], [1, 1, 0] ] w_key = torch.tensor(w_key, dtype=torch.float32) w_query = torch.tensor(w_query, dtype=torch.float32) w_value = https://www.fult.cn/torch.tensor(w_value, dtype=torch.float32)步骤3:派生键,查询和值
keys = x @ w_key querys = x @ w_query values = x @ w_value print(keys) # tensor([[0., 1., 1.], # [4., 4., 0.], # [2., 3., 1.]]) print(querys) # tensor([[1., 0., 2.], # [2., 2., 2.], # [2., 1., 3.]]) print(values) # tensor([[1., 2., 3.], # [2., 8., 0.], # [2., 6., 3.]步骤4:计算注意力分数
attn_scores = querys @ keys.T # tensor([[ 2., 4., 4.], # attention scores from Query 1 # [ 4., 16., 12.], # attention scores from Query 2 # [ 4., 12., 10.]]) # attention scores from Query 3
- 注意力分类及改善方法 注意力存在的症状及矫正方法
- 注意力不集中怎么缓解 注意力不集中应该怎么办
- 6-12岁孩子注意力不集中 小孩注意力不集中原因及治疗方法
- 真正稀缺的是注意力 注意力是稀缺资源
- 小朋友注意力不集中走神动作慢 小孩注意力不集中走神写作业拖拉
- 注意力的训练怎么提高 训练注意力有效方法
- 孩子总是注意力不集中上课老走神 孩子上课走神注意力不集中的表现
- 孩子注意力不集中如何帮他提高 提高孩子注意力不集中怎么训练
- 注意力稳定性的概念 注意力的概念界定
- 孩子注意力不集中怎么改掉 如何纠正孩子的注意力不集中
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。